In the Operating System, process data is loaded in fixed-sized chunks and each chunk is referred to as a page. The processor loads these pages in fixed-sized chunks of memory called frames. Typically the size of each page is always equal to the frame size.
A page fault occurs when a page is not found in the memory and needs to be loaded from the disk. If a page fault occurs and all memory frames have been already allocated, then the replacement of a page in memory is required at the request of a new page. This is referred to as demand-paging. The choice of which page to replace is specified by page replacement algorithms. The commonly used page replacement algorithms are FIFO, LRU, optimal page replacement algorithms, etc.
What is a Page Fault?
A page fault is a type of interrupt or exception that occurs in a computer’s operating system when a program attempts to access a page of memory that is not currently loaded into physical RAM (Random Access Memory). Instead, the page is stored on disk in a storage space called the page file or swap space.
Generally, on increasing the number of frames to a process’ virtual memory, its execution becomes faster as fewer page faults occur. Sometimes the reverse happens, i.e. more page faults occur when more frames are allocated to a process. This most unexpected result is termed Belady’s Anomaly.
What is a Belady’s Anomaly?
Bélády’s anomaly is the name given to the phenomenon where increasing the number of page frames results in an increase in the number of page faults for a given memory access pattern.
This phenomenon is commonly experienced in the following page replacement algorithms:
- First in first out (FIFO)
- Second chance algorithm
- Random page replacement algorithm
Reason for Belady’s Anomaly
The other two commonly used page replacement algorithms are Optimal and LRU, but Belady’s Anomaly can never occur in these algorithms for any reference string as they belong to a class of stack-based page replacement algorithms.
A stack-based algorithm is one for which it can be shown that the set of pages in memory for N frames is always a subset of the set of pages that would be in memory with N + 1 frames. For LRU replacement, the set of pages in memory would be the n most recently referenced pages. If the number of frames increases then these n pages will still be the most recently referenced and so, will still be in the memory. While in FIFO, if a page named b came into physical memory before a page – a then priority of replacement of b is greater than that of a, but this is not independent of the number of page frames and hence, FIFO does not follow a stack page replacement policy and therefore suffers Belady’s Anomaly.
Example: Consider the following diagram to understand the behavior of a stack-based page replacement algorithm

The diagram illustrates that given the set of pages i.e. {0, 1, 2} in 3 frames of memory is not a subset of the pages in memory – {0, 1, 4, 5} with 4 frames and it is a violation in the property of stack-based algorithms. This situation can be frequently seen in FIFO algorithm.
Belady’s Anomaly in FIFO
Assuming a system that has no pages loaded in the memory and uses the FIFO Page replacement algorithm. Consider the following reference string:
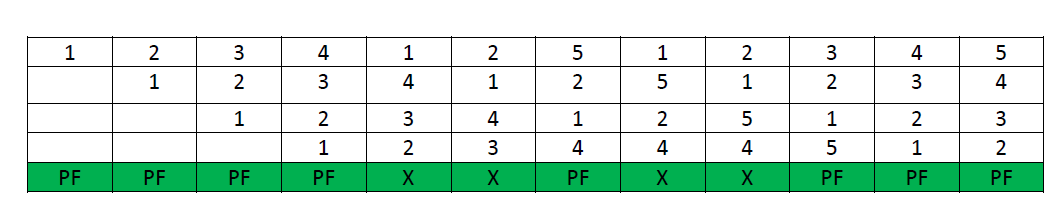
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
Case-1: If the system has 3 frames, the given reference string the using FIFO page replacement algorithm yields a total of 9 page faults. The diagram below illustrates the pattern of the page faults occurring in the example.

Case-2: If the system has 4 frames, the given reference string using the FIFO page replacement algorithm yields a total of 10 page faults. The diagram below illustrates the pattern of the page faults occurring in the example.

It can be seen from the above example that on increasing the number of frames while using the FIFO page replacement algorithm, the number of page faults increased from 9 to 10.
Note – It is not necessary that every string reference pattern cause Belady anomaly in FIFO but there is certain kind of string references that worsen the FIFO performance on increasing the number of frames.
Why Stack Based Algorithms do not Suffer Anomaly?
All the stack based algorithms never suffer Belady Anomaly because these type of algorithms assigns a priority to a page (for replacement) that is independent of the number of page frames. Examples of such policies are Optimal, LRU and LFU. Additionally these algorithms also have a good property for simulation, i.e. the miss (or hit) ratio can be computed for any number of page frames with a single pass through the reference string.
In LRU algorithm every time a page is referenced it is moved at the top of the stack, so, the top n pages of the stack are the n most recently used pages. Even if the number of frames is incremented to n+1, top of the stack will have n+1 most recently used pages.
Similar example can be used to calculate the number of page faults in LRU algorithm. Assuming a system that has no pages loaded in the memory and uses the LRU Page replacement algorithm. Consider the following reference string:
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
Case-1: If the system has 3 frames, the given reference string using the LRU page replacement algorithm yields a total of 10 page faults. The diagram below illustrates the pattern of the page faults occurring in the example.

Case-2: If the system has 4 frames, the given reference string on using LRU page replacement algorithm, then total 8 page faults occur. The diagram shows the pattern of the page faults in the example.
How Can Belady’s Anomaly Be Removed?
A stack-based approach can be used to get rid of Belady’s Algorithm. These are some examples of such algorithms:
- Optimal Page Replacement Algorithm
- Least Recently Used Algorithm (LRU)
These algorithms are based on the idea that if a page is inactive for a long time, it is not being utilised frequently. Therefore, it would be best to forget about this page. This allows for improvised memory management and the abolition of Belady’s anomaly.
Conclusion : Various factors substantially affect the number of page faults, such as reference string length and the number of free page frames available. Anomalies also occur due to the small cache size as well as the reckless rate of change of the contents of the cache. Also, the situation of a fixed number of page faults even after increasing the number of frames can also be seen as an anomaly. Often algorithms like Random page replacement algorithm are also susceptible to Belady’s Anomaly, because it may behave like first in first out (FIFO) page replacement algorithm. But Stack based algorithms are generally immune to all such situations as they are guaranteed to give better page hits when the frames are incremented.
Features of Belady’s Anomaly
- Page fault rate: Page fault rate is the number of page faults that occur during the execution of a process. Belady’s Anomaly occurs when the page fault rate increases as the number of page frames allocated to a process increases.
- Page replacement algorithm: Belady’s Anomaly is specific to some page replacement algorithms, including the First-In-First-Out (FIFO) algorithm and the Second-Chance algorithm.
- System workload: Belady’s Anomaly can occur when the system workload changes. Specifically, it can happen when the number of page references in the workload increases.
- Page frame allocation: Belady’s Anomaly can occur when the page frames allocated to a process are increased, but the total number of page frames in the system remains constant. This is because increasing the number of page frames allocated to a process reduces the number of page faults initially, but when the workload increases, the increased number of page frames can cause the process to evict pages from its working set more frequently, leading to more page faults.
- Impact on performance: Belady’s Anomaly can significantly impact system performance, as it can result in a higher number of page faults and slower overall system performance. It can also make it challenging to choose an optimal number of page frames for a process.
Advantages
- Better insight into algorithm behavior: Belady’s Anomaly can provide insight into how a page replacement algorithm works and how it can behave in different scenarios. This can be helpful in designing and optimizing algorithms for specific use cases.
- Improved algorithm performance: In some cases, increasing the number of frames allocated to a process can actually improve algorithm performance, even if it results in more page faults. This is because having more frames can reduce the frequency of page replacement, which can improve overall performance.
Disadvantages
- Poor predictability: Belady’s Anomaly can make it difficult to predict how an algorithm will perform with different configurations of frames and pages, which can lead to unpredictable performance and system instability.
- Increased overhead: In some cases, increasing the number of frames allocated to a process can result in increased overhead and resource usage, which can negatively impact system performance.
- Unintuitive behavior: Belady’s Anomaly can result in unintuitive behavior, where increasing the number of frames allocated to a process results in more page faults, which can be confusing for users and system administrators.
- Difficulty in optimization: Belady’s Anomaly can make it difficult to optimize page replacement algorithms for specific use cases, as the behavior of the algorithm can be unpredictable and inconsistent.
Conclusion
A page fault occurs when a program accesses a page not currently in RAM, triggering a process to load the page from disk. Belady’s Anomaly describes the counterintuitive situation where increasing the number of memory frames can lead to more page faults with some algorithms, like FIFO. This anomaly highlights the importance of choosing efficient page replacement algorithms. Stack-based algorithms, such as LRU and Optimal, are immune to Belady’s Anomaly and typically provide more predictable performance.
GATE CS Corner Questions
Practicing the following questions will help you test your knowledge. All questions have been asked in GATE in previous years or in GATE Mock Tests. It is highly recommended that you practice them.
- GATE-CS-2001 | Question 21
- GATE-CS-2009 | Question 8
- ISRO CS 2011 | Question 73
- GATE-CS-2016 (Set 2) | Question 30
- ISRO CS 2016 | Question 48
- GATE CS Mock 2018 | Question 63
Frequently Asked Questions on Belady’s Anomaly – FAQs
What is a page fault?
A page fault occurs when a program tries to access a page of memory that is not currently loaded into physical RAM. The operating system must then load the required page from disk into RAM, which can cause a delay in execution.
What is Belady’s Anomaly?
Belady’s Anomaly is a phenomenon where increasing the number of page frames allocated to a process results in an increase in the number of page faults, contrary to the expected decrease. This anomaly is typically observed in certain page replacement algorithms, such as FIFO.
Which page replacement algorithms are affected by Belady’s Anomaly?
Belady’s Anomaly commonly affects algorithms like First-In-First-Out (FIFO), Second-Chance, and Random page replacement. These algorithms do not follow stack-based policies and can show increased page faults with more frames.
How can Belady’s Anomaly be avoided?
Belady’s Anomaly can be avoided by using stack-based page replacement algorithms, such as Least Recently Used (LRU) or Optimal Page Replacement. These algorithms ensure that increasing the number of frames does not lead to more page faults.
Please Login to comment...