A Tourist Attraction Recommendation Model Fusing Spatial, Temporal, and Visual Embeddings for Flickr-Geotagged Photos


Abstract
:1. Introduction
- Given the CF-based models’ cold-start problems and the content-based models’ low accuracy problems, we propose a hybrid recommendation model for tourist attractions that fuses spatial, temporal, and visual embeddings (STVE).
- We modify Skip-gram’s objective function to model the sequential factors in STVE, which takes advantage of Skip-gram’s characteristics that handle the sequential data well and is more in line with the actual tourist attraction recommendation scenario.
- Given the problems that the noisy and redundant photos may exert a bad influence on the extraction of visual embeddings and the recommendation results, we propose a framework that can automatically remove the noisy and redundant photos and select representative images to extract visual embeddings of the tourist attractions for further use.
2. Related Work
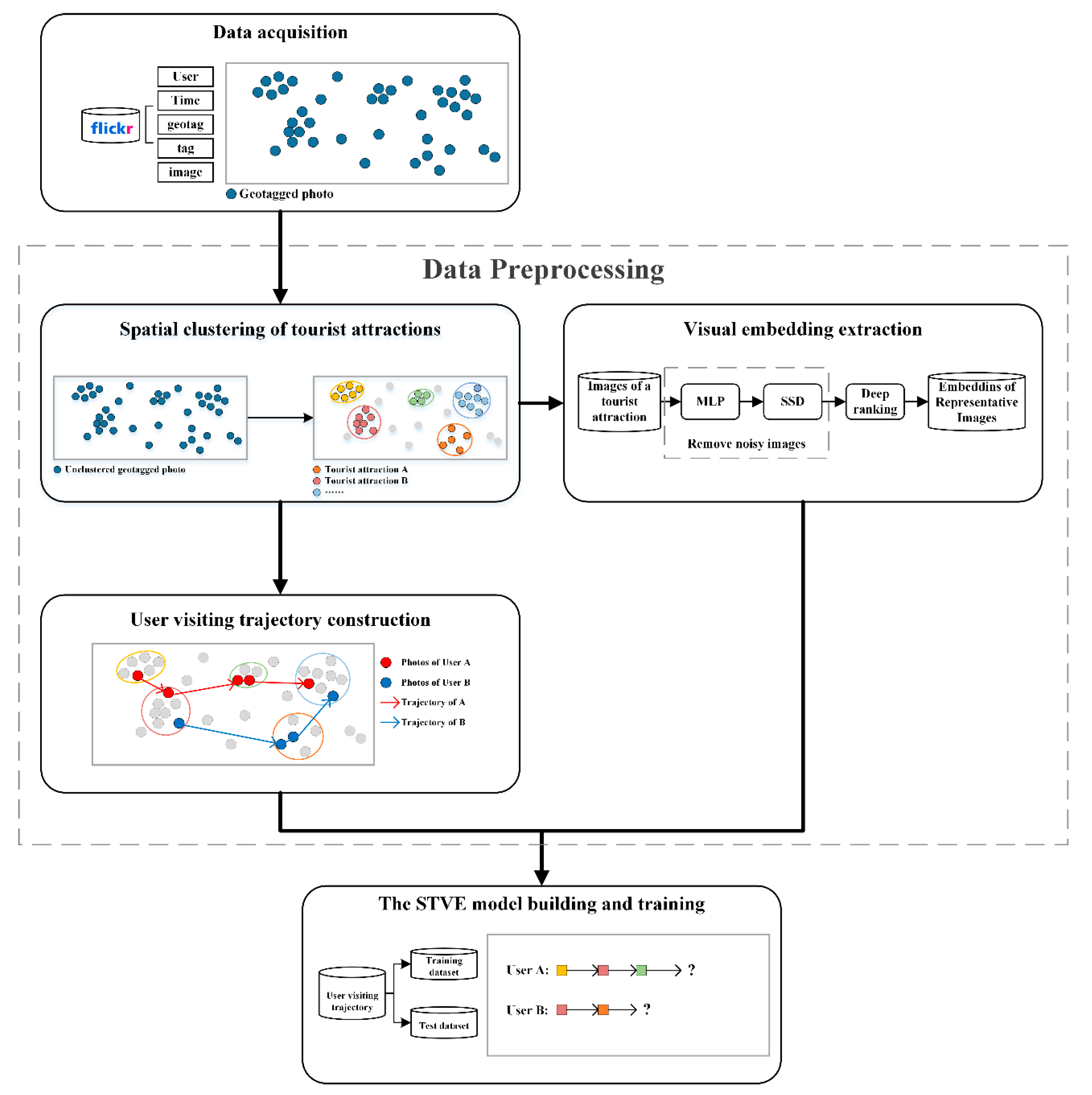
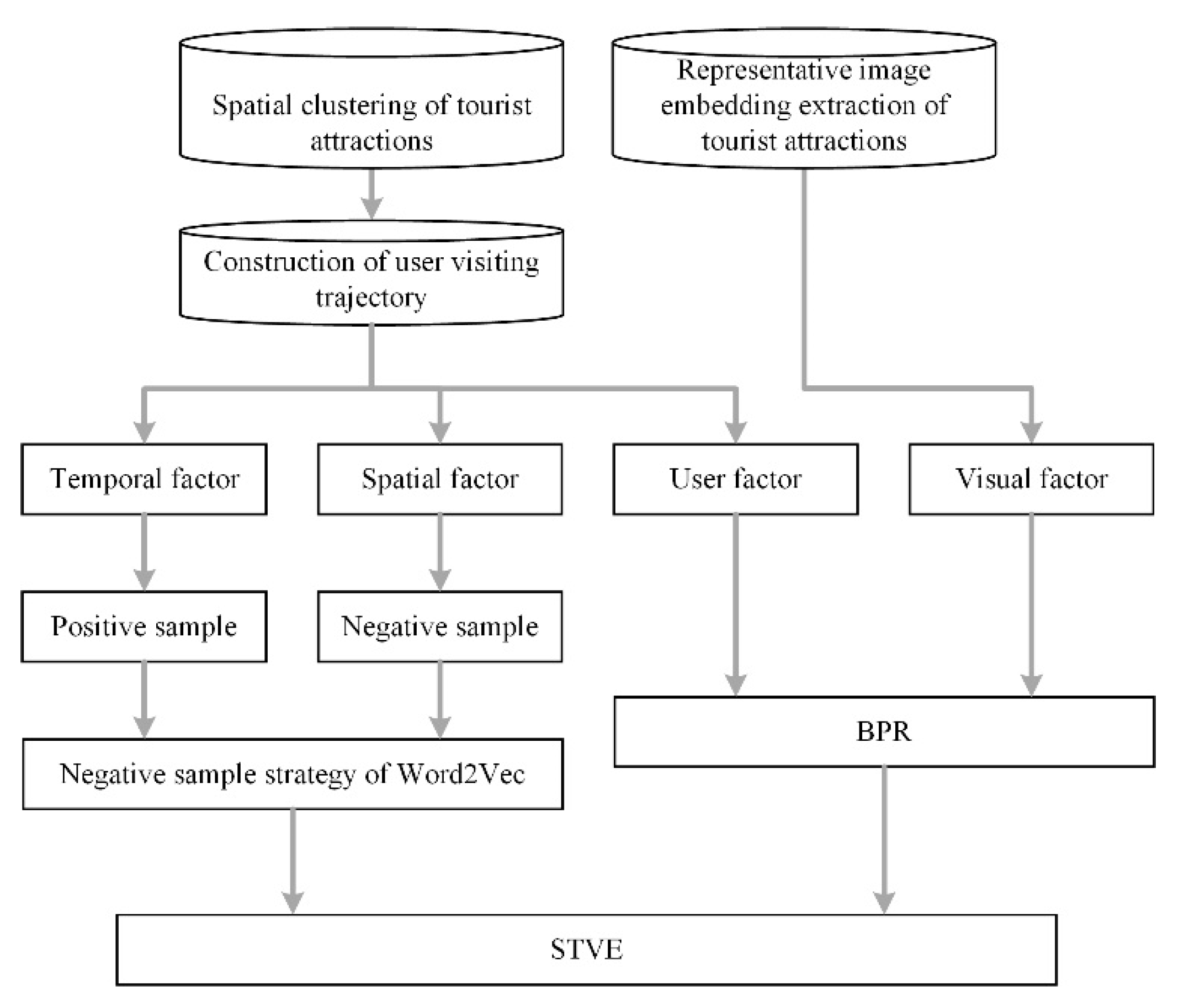
3. Methodology
3.1. Preliminary and Framework
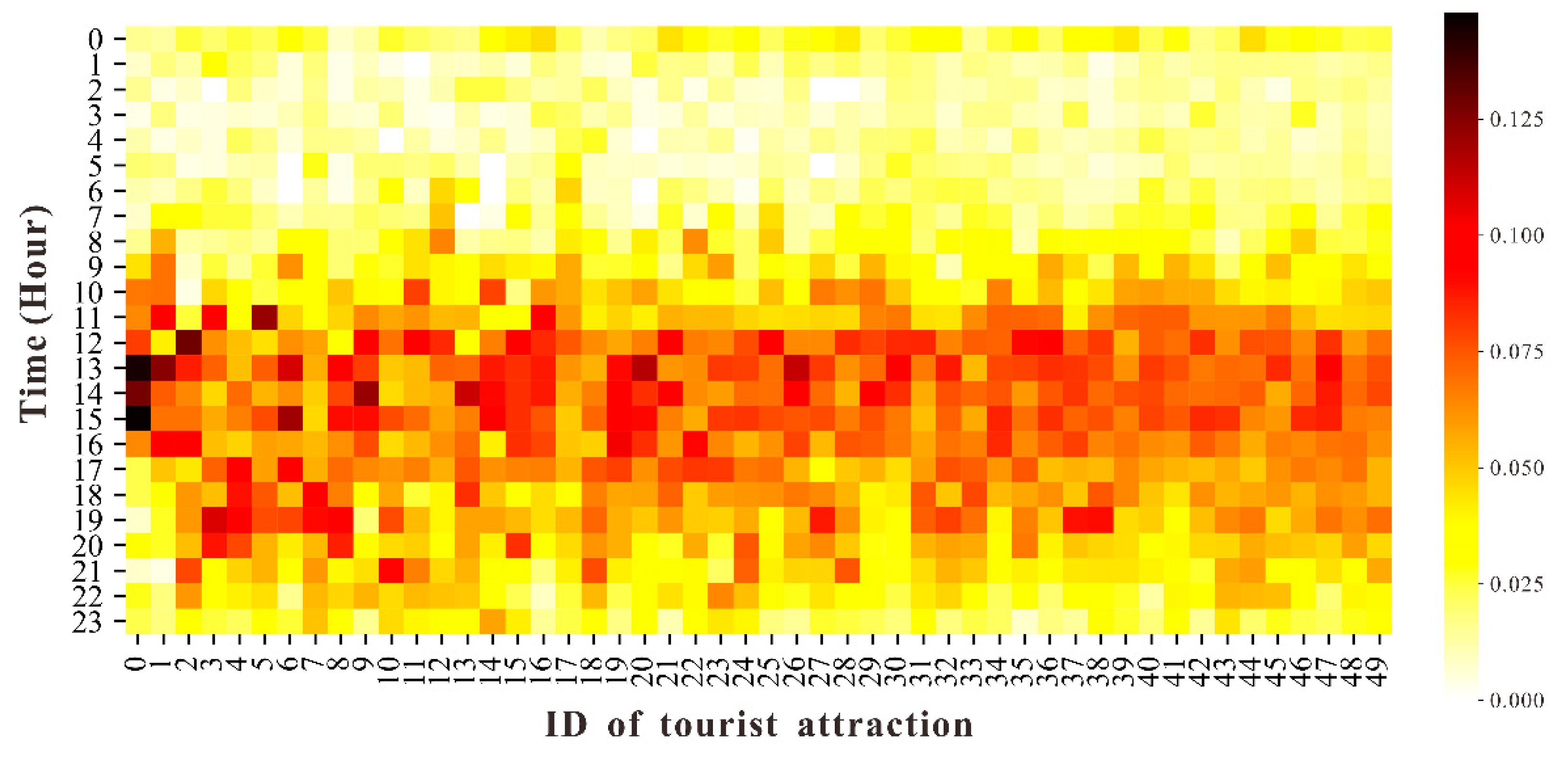
3.2. Dataset and Study Area
3.3. Data Preprocessing
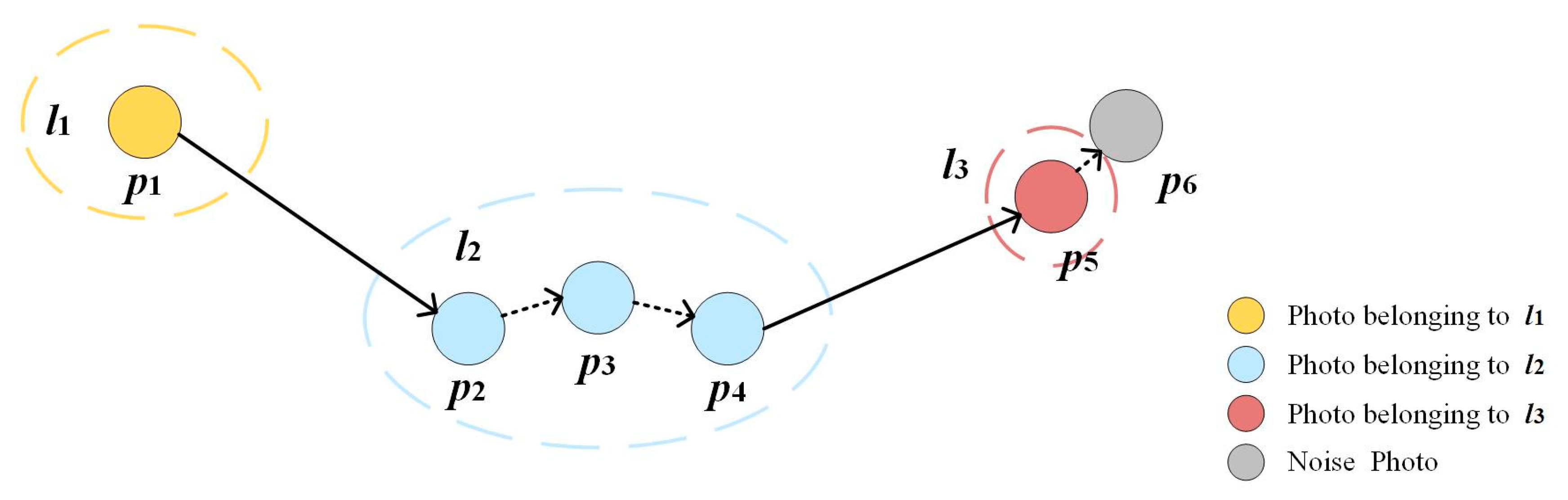
3.3.1. Spatial Clustering of Tourist Attractions
3.3.2. Visual Embedding Extraction
3.3.3. User Visiting Trajectory Construction
3.4. Model Description and Optimization
3.4.1. Spatial–Temporal Embedding
3.4.2. Visual Embedding
3.4.3. Model Learning
| Algorithm 1: the STVE model | |
| Input: | -dataset; ; -the number of epoch; –the ratio of batch size; -the learning rate of ; -the learning rate of ; -cut distance; -the number of negative sample in ; -the number of negative sample in ; -regularization parameter. |
| Output: | |
| 1 | Initialize with Normal Distribution |
| 2 | for; do |
| 3 | RandomlySelect (,) |
| 4 | for ; ; do |
| 5 | for ; ; do |
| 6 | if do |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | for ; ; do |
| 12 | |
| 13 | |
| 14 | |
| 15 | end |
| 16 | end |
| 17 | for ; ; do |
| 18 | |
| 19 | |
| 20 | |
| 21 | end |
| 22 | end |
| 23 | end |
| 24 | end |
4. Experimental Result
4.1. Experiment Settings
4.1.1. Evaluation Metrics
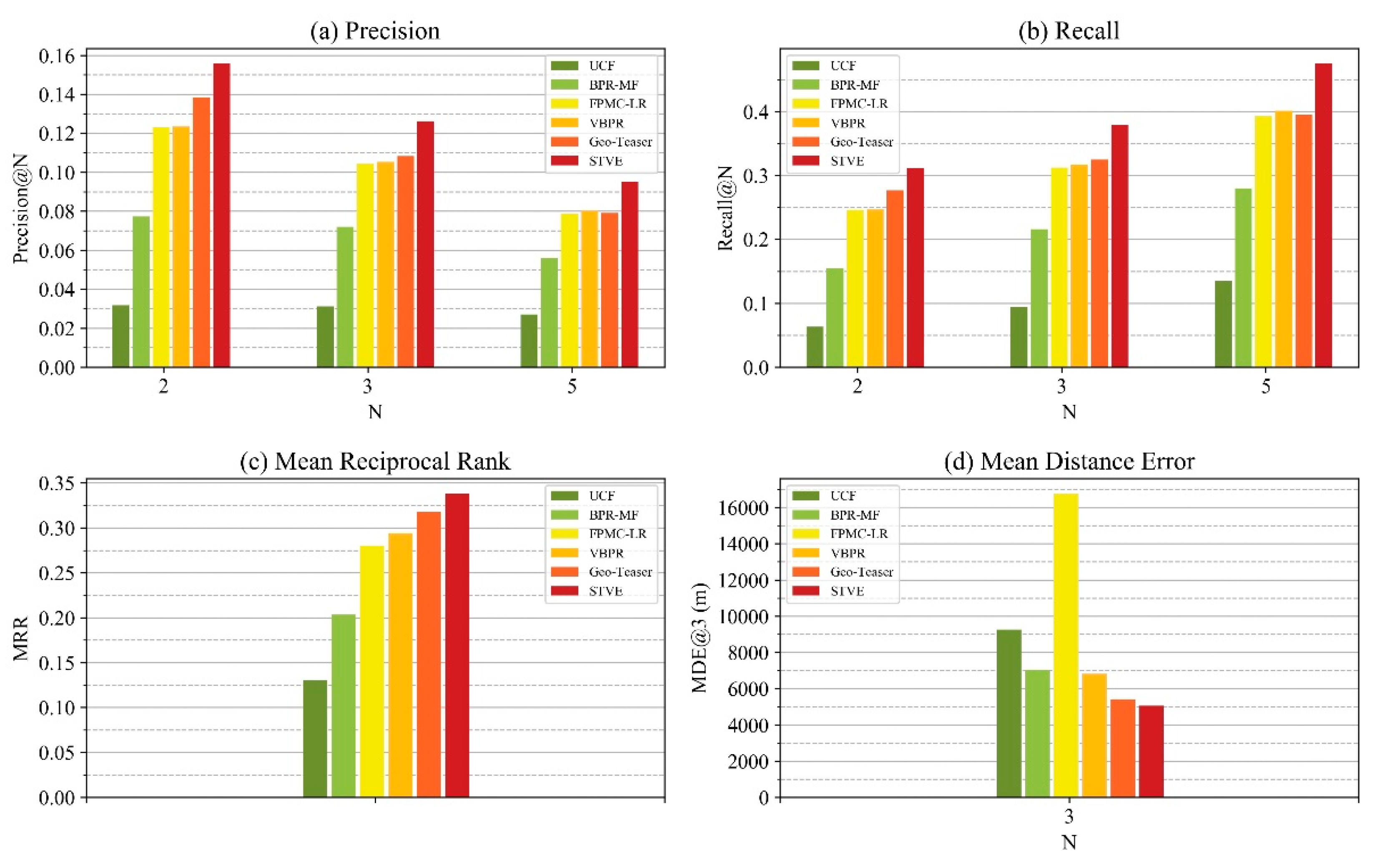
4.1.2. Comparison Methods
- Bayesian Personalized Ranking-Matrix Factorization (BPR-MF): BPR-MF is a simple “user-item” matrix factorization method optimized with Bayesian Personalized Ranking.
- VBPR: VBPR is a matrix factorization model with visual information aimed at online shopping recommendations [44].
- Geo-Teaser: Geo-Teaser was a method that integrates temporal and geographical information with the negative sampling strategy of Word2Vec and hierarchical pairwise ranking to make recommendations [19].
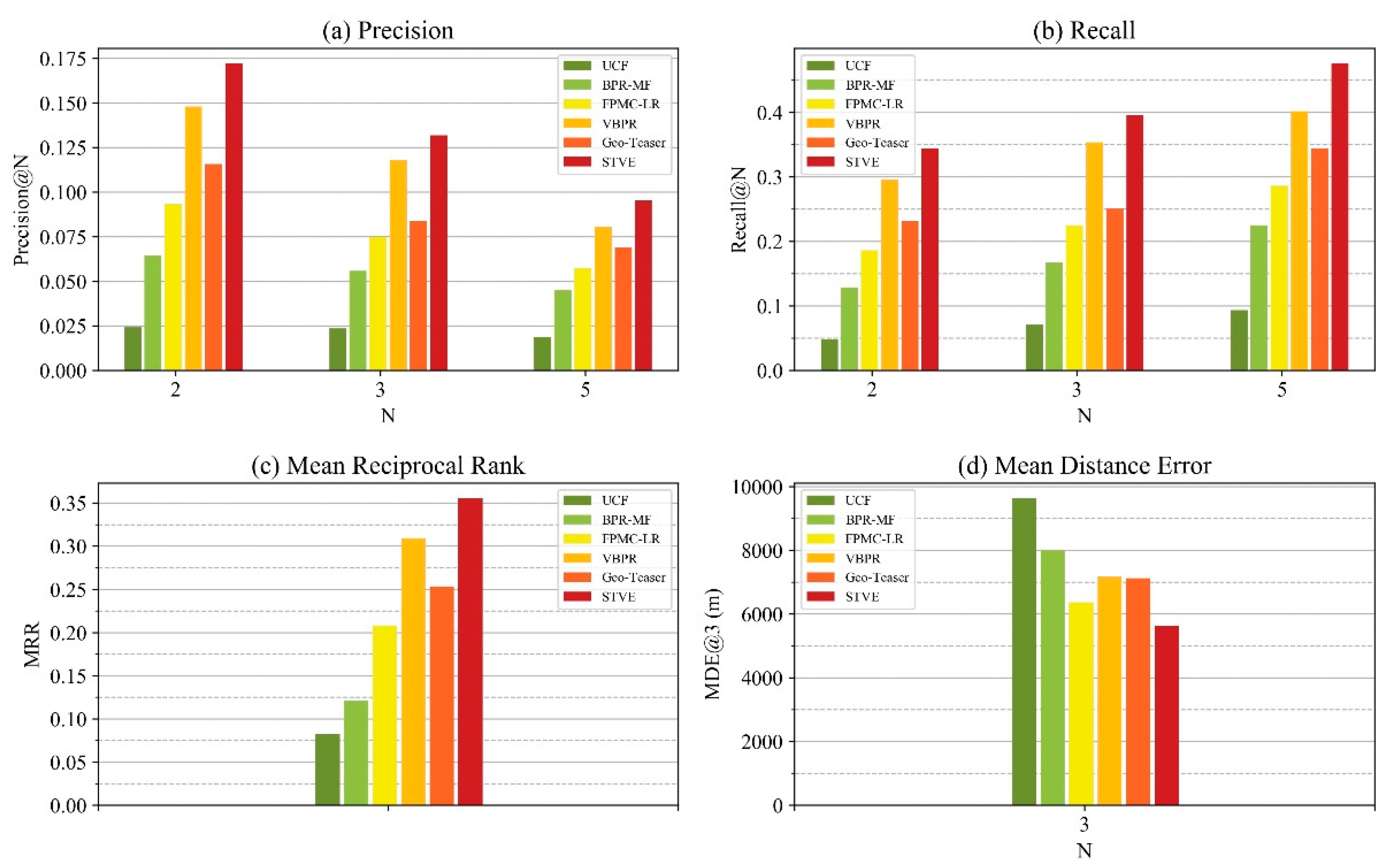
4.2. Performance Comparison
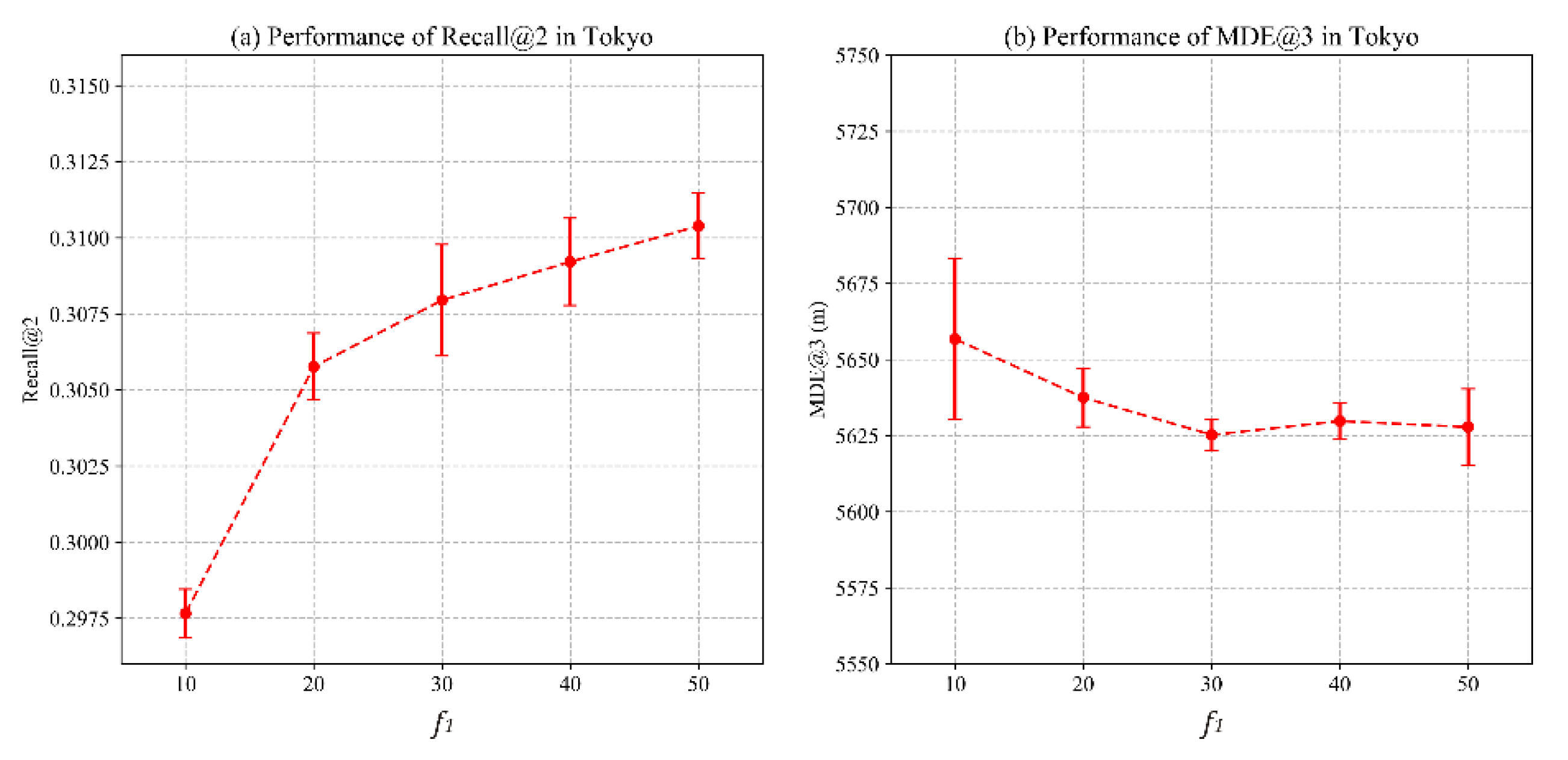
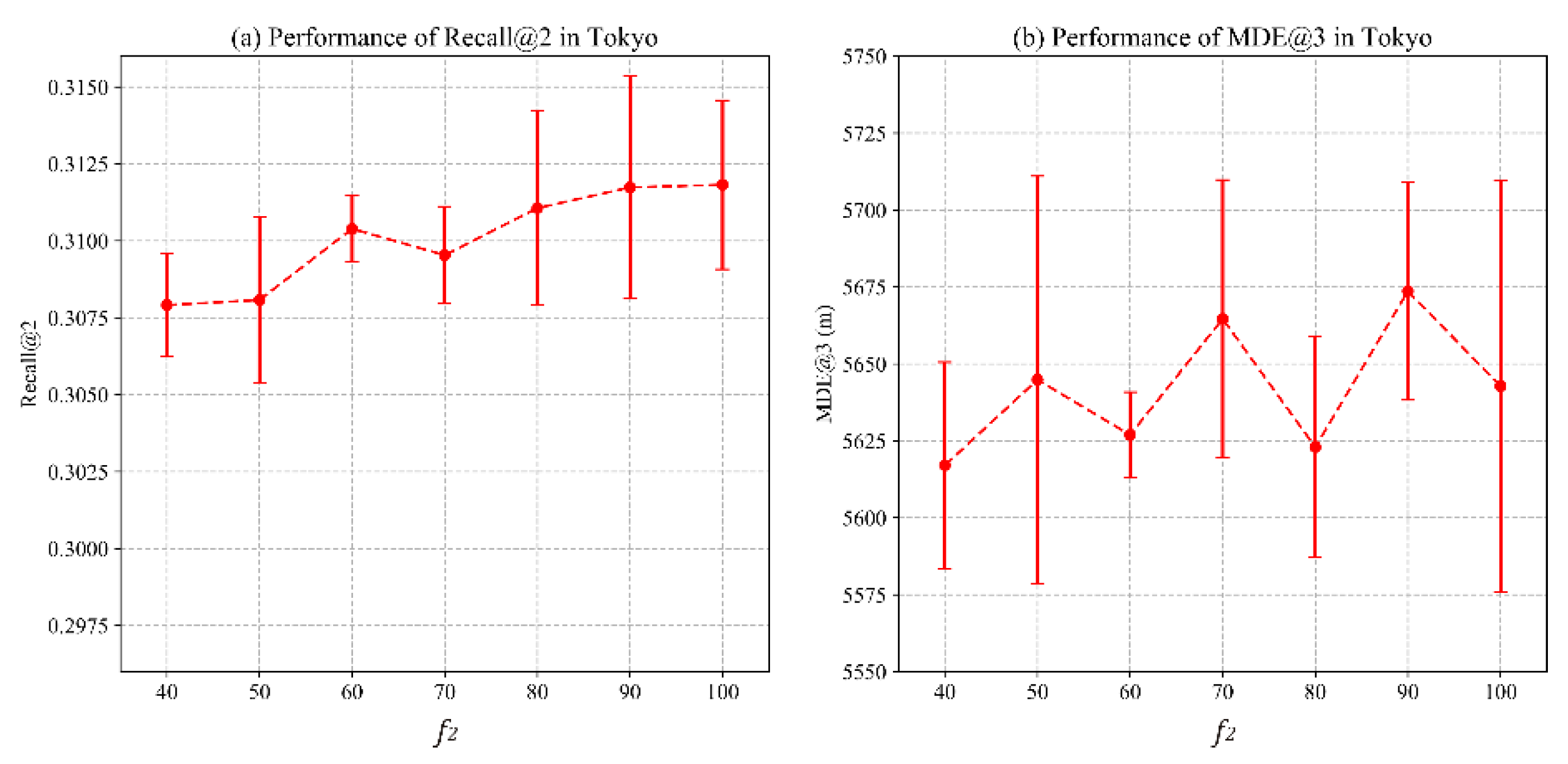
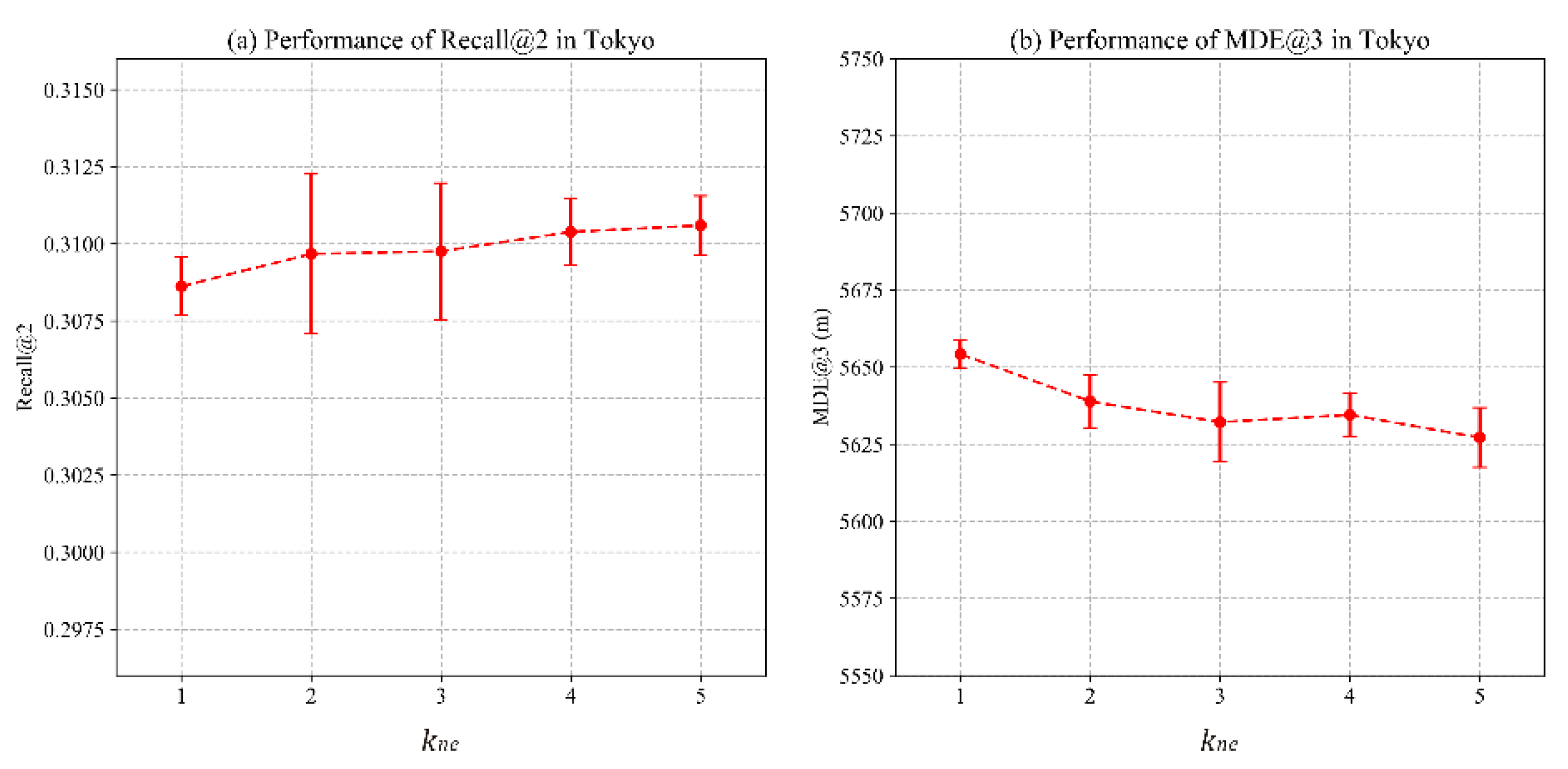
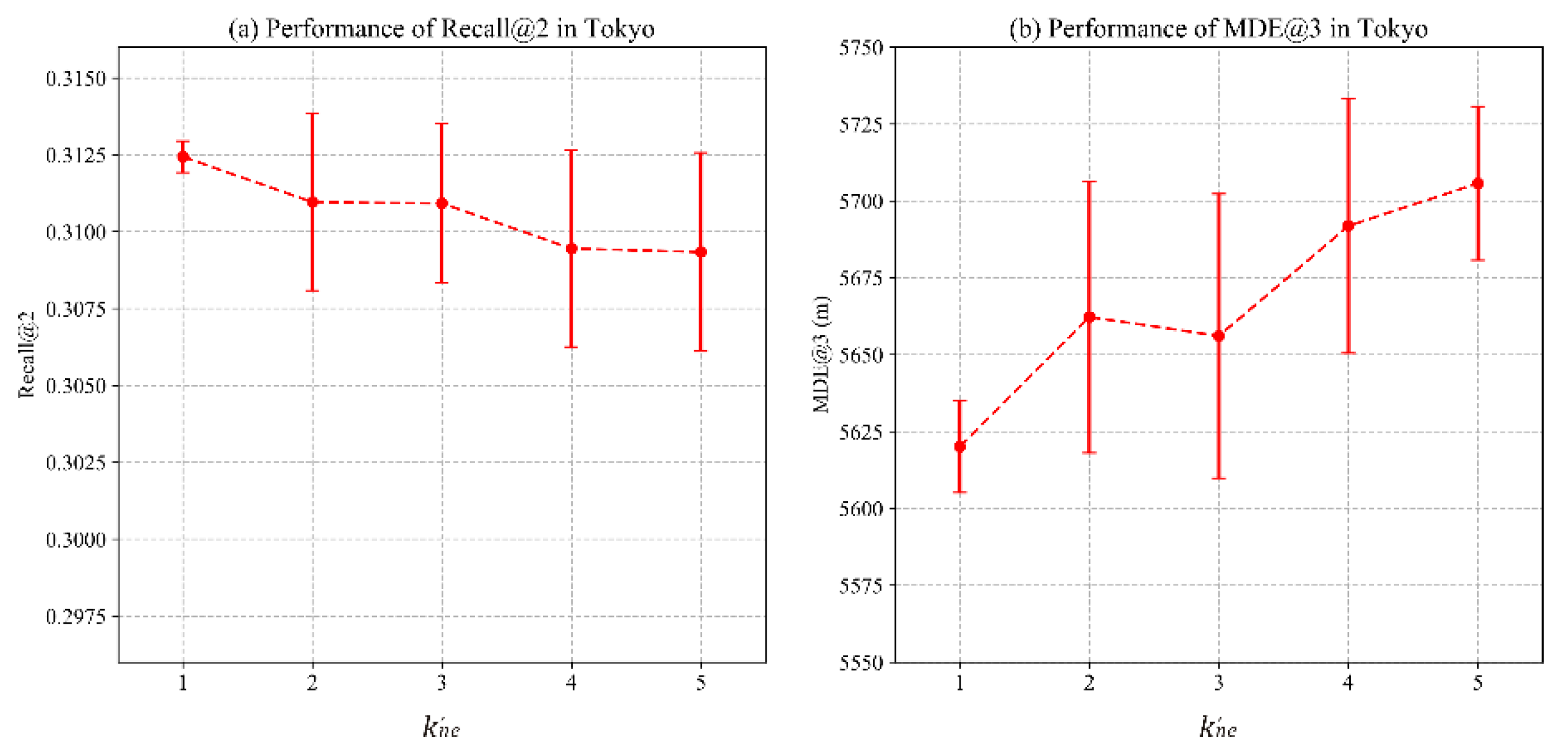
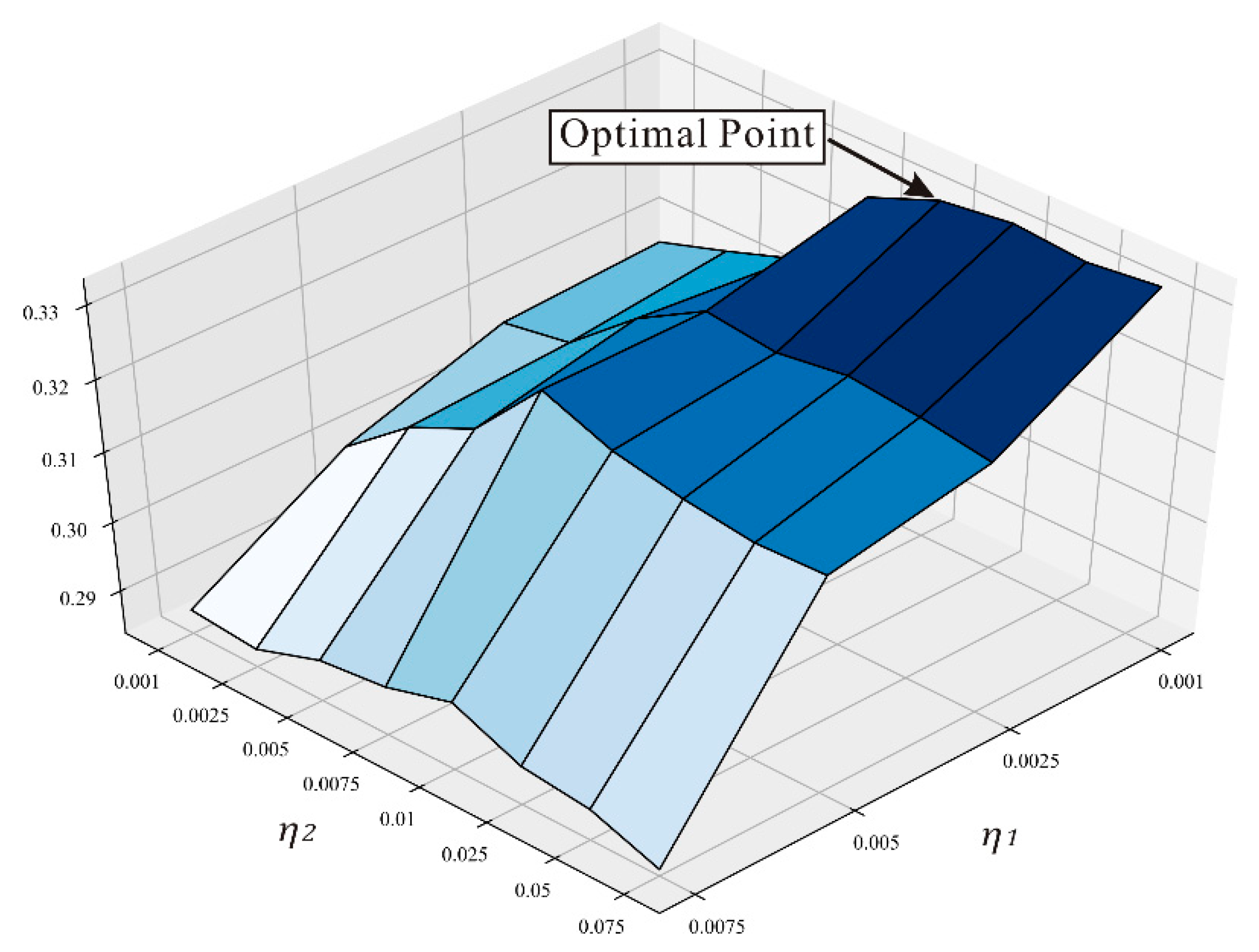
4.3. Parameter Sensitivity Analysis
4.3.1. Impact of Dimension
4.3.2. Impact of Negative Samples
4.3.3. Impact of Learning Rate
4.4. Component-Wise Study
4.5. Results for Cold-Start User
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hendler, J. Web 3.0 Emerging. Computer 2009, 42, 111–113. [Google Scholar] [CrossRef]
- Rudman, R.; Bruwer, R. Defining Web 3.0: Opportunities and challenges. Electron. Libr. 2016, 34, 132–154. [Google Scholar] [CrossRef]
- World Travel & Tourism Council. Available online: https://www.wttc.org (accessed on 25 February 2020).
- World Tourism Organization. UNWTO Tourism Highlights, 2019th ed.; UNWTO: Madrid, Spain, 2018. [Google Scholar]
- Report of Global Independent Travel. 2017. Available online: http://www.mafengwo.cn/activity/sales_.report2017/index (accessed on 28 December 2019).
- Gao, Y.; Tang, J.; Hong, R.; Dai, Q.; Chua, T.S.; Jain, R. W2Go: A travel guidance system by automatic landmark ranking. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 123–132. [Google Scholar]
- Zhou, X.; Xu, C.; Kimmons, B. Detecting tourism destinations using scalable geospatial analysis based on cloud computing platform. Comput. Environ. Urban Syst. 2015, 54, 144–153. [Google Scholar] [CrossRef]
- Rafsanjani, A.H.N.; Salim, N.; Aghdam, A.R.; Fard, K.B. Recommendation Systems: A review. Int. J. Comput. Eng. Res. 2013, 3, 47–52. [Google Scholar]
- Van Meteren, R.; Van Someren, M. Using content-based filtering for recommendation. In Proceedings of the Machine Learning in the New Information Age MLnet/ECML2000 Workshop, Barcelona, Spain, 30 May 2000; pp. 47–56. [Google Scholar]
- Schafer, J.B.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative Filtering Recommender Systems; Springer: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M.F. Recommendations in location-based social networks: A survey. GeoInformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Adomavicius, G.; Sankaranarayanan, R.; Sen, S.; Tuzhilin, A. Incorporating contextual information in recommender systems using a multidimensional approach. ACM Trans. Inf. Syst. 2005, 23, 103–145. [Google Scholar] [CrossRef] [Green Version]
- Renjith, S.; Sreekumar, A.; Jathavedan, M. An extensive study on the evolution of context-aware personalized travel recommender systems. Inform. Process. Manag. 2020, 57, 102078. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th international conference on Architectural support for programming languages and operating systems; Association for Computing Machinery (ACM), Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Feng, S.; Li, X.; Zeng, Y.; Chee, Y.M. Personalized ranking metric embedding for next new poi recommendation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2069–2075. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, New York, NY, USA, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Xie, M.; Yin, H.; Wang, H.; Xu, F.; Chen, W.; Wang, S. Learning graph-based poi embedding for location-based recommendation. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 15–24. [Google Scholar]
- Zhao, S.; Zhao, T.; King, I.; Lyu, M.R. Geo-teaser: Geo-temporal sequential embedding rank for point-of-interest recom-mendation. In Proceedings of the 26th International Conference on World Wide Web Companion, Geneva, Switzerland, 3–7 April 2017; pp. 153–162. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.-C.; Lee, D.-L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information—SIGIR ’11, Beijing, China, 25–29 July 2011; pp. 325–334. [Google Scholar]
- Zhang, Z.; Zou, C.; Ding, R.; Chen, Z. VCG: Exploiting visual contents and geographical influence for Point-of-Interest recommendation. Neurocomputing 2019, 357, 53–65. [Google Scholar] [CrossRef]
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. Fused matrix factorization with geographical and social influence in location-based social networks. In Proceedings of the Twentysixth AAAI conference on artificial intelligence, Toronto, ON, Canada, 22 July 2012; pp. 17–23. [Google Scholar]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 831–840. [Google Scholar]
- He, J.; Li, X.; Liao, L.; Song, D.; Cheung, W.K. Inferring a personalized next point-of-interest recommendation model with latent behavior patterns. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 137–143. [Google Scholar]
- Gao, H.; Tang, J.; Huan, L.; Liu, H. Exploring temporal effects for location recommendation on location-based social networks. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–17 October 2013; pp. 93–100. [Google Scholar]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th international ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’13, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar]
- Shi, Y.; Serdyukov, P.; Hanjalic, A.; Larson, M. Personalized landmark recommendation based on geotags from photo sharing sites. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Memon, I.; Chen, L.; Majid, A.; Lv, M.; Hussain, I.; Chen, G. Travel recommendation using geo-tagged photos in social media for tourist. Kluw. Commun. 2015, 80, 1347–1362. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Cheng, A.-J.; Hsu, W.H. Travel Recommendation by Mining People Attributes and Travel Group Types from Community-Contributed Photos. IEEE Trans. Multimed. 2013, 15, 1283–1295. [Google Scholar] [CrossRef]
- Subramaniyaswamy, V.; Vijayakumar, V.; Logesh, R.; Indragandhi, V. Intelligent Travel Recommendation System by Mining Attributes from Community Contributed Photos. Procedia Comput. Sci. 2015, 50, 447–455. [Google Scholar] [CrossRef] [Green Version]
- AlBanna, B.; Sakr, M.; Moussa, S.; Moawad, I. Interest Aware Location-Based Recommender System Using Geo-Tagged Social Media. ISPRS Int. J. Geo.-Inf. 2016, 5, 245. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Zhou, X.; Shi, W.; Zhang, A. Recommending attractive thematic regions by semantic community detection with multisourced VGI data. Int. J. Geogr. Inf. Sci. 2019, 33, 1520–1544. [Google Scholar] [CrossRef]
- Cao, L.; Luo, J.; Gallagher, A.; Jin, X.; Han, J.; Huang, T.S. A worldwide tourism recommendation system based on geotagged web photos. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 2274–2277. [Google Scholar]
- Jiang, K.; Wang, P.; Yu, N. ContextRank: Personalized tourism recommendation by exploiting context information of geotagged web photos. In Proceedings of the 2011 Sixth International Conference on Image and Graphics, Hefei, China, 12–15 August 2011; pp. 931–937. [Google Scholar]
- Wang, S.; Wang, Y.; Tang, J.; Shu, K.; Ranganath, S.; Liu, H. What your images reveal: Exploiting visual contents for point-of-interest recommendation. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 391–400. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Menk, A.; Sebastia, L.; Ferreira, R. Recommendation Systems for Tourism Based on Social Networks: A Survey. arXiv 2019, arXiv:1903.12099. [Google Scholar]
- Survey Concerning Visitors to Tokyo in 2018. Available online: http://www.metro.tokyo.jp/english/topics/.2019/0828_01.html (accessed on 20 December 2019).
- Han, S.; Ren, F.; Du, Q.; Gui, D. Extracting Representative Images of Tourist Attractions from Flickr by Combining an Improved Cluster Method and Multiple Deep Learning Models. ISPRS Int. J. Geo.-Inf. 2020, 9, 81. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning Fine-Grained Image Similarity with Deep Ranking. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Li, F.L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories. Comput. Vis. Image Und. 2007, 106, 59–70. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [Green Version]
- He, R.; McAuley, J. VBPR: Visual Bayesian Personalized Ranking from implicit feedback. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 144–150. [Google Scholar]
- Yao, D.; Zhang, C.; Huang, J.; Bi, J. Serm: A recurrent model for next location prediction in semantic trajectories. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2411–2414. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Majid, A.; Chen, L.; Chen, G.; Mirza, H.T.; Hussain, I.; Woodward, J. A context-aware personalized travel recommendation system based on geotagged social media data mining. Int. J. Geogr. Inf. Sci. 2013, 27, 662–684. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| the training dataset for all users in the study area | |
| , | a user and a tourist attraction |
| , | the -th and -th tourist attractions visited by the user |
| the time slot of the user to visit his/her -th attractions | |
| , | the -dimensional embedding representations of and |
| the -dimensional embedding representations of | |
| the -dimensional embedding representations of user | |
| the visual embeddings of representative images for the attraction | |
| , | the number of negative samples for spatial-temporal embeddings and visual embeddings |
| , | the negative sample attractions for spatial-temporal embeddings and visual embeddings |
| the number of dimensions for , and . | |
| the number of dimensions for | |
| the number of dimensions for visual embeddings | |
| embedding matrix |
| Component/ Model | Evaluation Metrics | |||
|---|---|---|---|---|
| P@2 | R@2 | MDE@3 | MRR | |
| ST | 0.1495 | 0.3045 | 5925.6213 | 0.3275 |
| T | 0.1464 | 0.2978 | 6893.4233 | 0.3169 |
| V | 0.0916 | 0.1832 | 8119.1503 | 0.2395 |
| STVE | 0.1557 | 0.3114 | 5660.6962 | 0.3378 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, S.; Liu, C.; Chen, K.; Gui, D.; Du, Q. A Tourist Attraction Recommendation Model Fusing Spatial, Temporal, and Visual Embeddings for Flickr-Geotagged Photos. ISPRS Int. J. Geo-Inf. 2021, 10, 20. https://doi.org/10.3390/ijgi10010020
Han S, Liu C, Chen K, Gui D, Du Q. A Tourist Attraction Recommendation Model Fusing Spatial, Temporal, and Visual Embeddings for Flickr-Geotagged Photos. ISPRS International Journal of Geo-Information. 2021; 10(1):20. https://doi.org/10.3390/ijgi10010020
Chicago/Turabian StyleHan, Shanshan, Cuiming Liu, Keyun Chen, Dawei Gui, and Qingyun Du. 2021. "A Tourist Attraction Recommendation Model Fusing Spatial, Temporal, and Visual Embeddings for Flickr-Geotagged Photos" ISPRS International Journal of Geo-Information 10, no. 1: 20. https://doi.org/10.3390/ijgi10010020