Kinematska Kontrola
Kinematska Kontrola
Download as pdf or txt
You might also like
- Bollobas, B. - The Art of Mathematics, Coffee Time in MemphisDocument376 pagesBollobas, B. - The Art of Mathematics, Coffee Time in MemphisGabi Tóth100% (3)
- Lec19 - Linear Quadratic RegulatorDocument7 pagesLec19 - Linear Quadratic RegulatorPilwon HurNo ratings yet
- Aft NotesDocument81 pagesAft NotesNhellCernaNo ratings yet
- AP Physics Linearizing Data PracticeDocument2 pagesAP Physics Linearizing Data PracticeHuiqiNo ratings yet
- 03 LagrangianDynamics 1Document28 pages03 LagrangianDynamics 1Terence Deng100% (1)
- Vibrations in Engineering: Faculty of Civil Engineering and Applied MechanicsDocument133 pagesVibrations in Engineering: Faculty of Civil Engineering and Applied Mechanicsvuhoangdai90No ratings yet
- Review of Dynamics and Mechanisms of Machinery: MECH 103Document92 pagesReview of Dynamics and Mechanisms of Machinery: MECH 103Sunilkumar ReddyNo ratings yet
- First Integrals. Reduction. The 2-Body ProblemDocument19 pagesFirst Integrals. Reduction. The 2-Body ProblemShweta SridharNo ratings yet
- Dynamic Analysis Using FEMDocument47 pagesDynamic Analysis Using FEMB S Praveen BspNo ratings yet
- L7 - Engineering Method For Dynamic AeroelasticityDocument19 pagesL7 - Engineering Method For Dynamic AeroelasticityAbaziz Mousa OutlawZz100% (1)
- 2425 FormulasDocument2 pages2425 FormulasSandeep K. JaiswalNo ratings yet
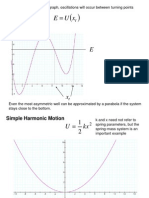
- Given A Potential Energy Graph, Oscillations Will Occur Between Turning Points Determined byDocument9 pagesGiven A Potential Energy Graph, Oscillations Will Occur Between Turning Points Determined byjdlawlisNo ratings yet
- Bifurcation in The Dynamical System With ClearancesDocument6 pagesBifurcation in The Dynamical System With Clearancesklomps_jrNo ratings yet
- T6lekk Mmbmro HF1 PDFDocument11 pagesT6lekk Mmbmro HF1 PDFBenci MonoriNo ratings yet
- 1st Integral PDFDocument19 pages1st Integral PDFAtique KhanNo ratings yet
- 2 Denis Mosconi - RevisadoDocument8 pages2 Denis Mosconi - RevisadoDenis MosconiNo ratings yet
- 15.1 Dynamic OptimizationDocument32 pages15.1 Dynamic OptimizationDaniel Lee Eisenberg JacobsNo ratings yet
- Elementary Tutorial: Fundamentals of Linear VibrationsDocument51 pagesElementary Tutorial: Fundamentals of Linear VibrationsfujinyuanNo ratings yet
- Systems of Surveillance of Dynamic ProcessesDocument13 pagesSystems of Surveillance of Dynamic ProcessesnickNo ratings yet
- Lecture 23Document8 pagesLecture 23YERRAMSETTY CHAITANYANo ratings yet
- AQA M1 Revision NotesDocument9 pagesAQA M1 Revision NotesLscribd15No ratings yet
- Control Lecture 8 Poles Performance and StabilityDocument20 pagesControl Lecture 8 Poles Performance and StabilitySabine Brosch100% (1)
- ADL Dottorato2011 Part1 SlidesDocument72 pagesADL Dottorato2011 Part1 SlidesDennis SanNo ratings yet
- Chap 1 Preliminary Concepts: Nkim@ufl - EduDocument20 pagesChap 1 Preliminary Concepts: Nkim@ufl - Edudozio100% (1)
- Variable Structure Control Mechanical Systems: Harry G. KwatnyDocument15 pagesVariable Structure Control Mechanical Systems: Harry G. KwatnyChernet TugeNo ratings yet
- Short NotesDocument16 pagesShort NotesRahique ShuaibNo ratings yet
- Mechanics Chapter 1 and 2 Presentation Written by Kleppner and KollenknowDocument53 pagesMechanics Chapter 1 and 2 Presentation Written by Kleppner and Kollenknowsaigautham123No ratings yet
- Athans Workshop 10 07Document40 pagesAthans Workshop 10 07Anonymous JvDVQVNo ratings yet
- Chapter 5: Image Transforms: (From Anil. K. Jain)Document35 pagesChapter 5: Image Transforms: (From Anil. K. Jain)Jacob HowardNo ratings yet
- PHY2014F Buffler VW1Document125 pagesPHY2014F Buffler VW1Matthew BaileyNo ratings yet
- Motor Control: Operator Input Power SupplyDocument27 pagesMotor Control: Operator Input Power Supplykubu2689No ratings yet
- System Simulation Using Matlab, State Plane PlotsDocument7 pagesSystem Simulation Using Matlab, State Plane PlotsmosictrlNo ratings yet
- Equations of Change ChE 131Document34 pagesEquations of Change ChE 131Johanna Martinne CanlasNo ratings yet
- System Response System Response: Chew Chee Meng Department of Mechanical Engineering National University of SingaporeDocument33 pagesSystem Response System Response: Chew Chee Meng Department of Mechanical Engineering National University of SingaporeLincoln ZhaoXiNo ratings yet
- Non Linear Optimal Swing Up of An Inverted Pendulum On A Cart Using Pontryagin's Principle With Fixed Final TimeDocument8 pagesNon Linear Optimal Swing Up of An Inverted Pendulum On A Cart Using Pontryagin's Principle With Fixed Final TimeMatteo RocchiNo ratings yet
- Chapter 1 & 2 - Introduction To Vibrations and Single DOF SystemsDocument86 pagesChapter 1 & 2 - Introduction To Vibrations and Single DOF SystemsMohamad Faiz TonyNo ratings yet
- DCTDocument32 pagesDCTAmardeep KumarNo ratings yet
- Chapter 4 Multiple-Degree-of-Freedom (MDOF) Systems ExamplesDocument17 pagesChapter 4 Multiple-Degree-of-Freedom (MDOF) Systems ExamplesprashanthNo ratings yet
- AQA Mechanics 1 Revision NotesDocument9 pagesAQA Mechanics 1 Revision Notesdeyaa1000000No ratings yet
- Edexcel M1 Reviosn NotesDocument9 pagesEdexcel M1 Reviosn NotesHamza Baig100% (1)
- MST207 04Document6 pagesMST207 04pigcowdogNo ratings yet
- ENGR 6925: Automatic Control Engineering Supplementary Notes On ModellingDocument31 pagesENGR 6925: Automatic Control Engineering Supplementary Notes On ModellingTharakaKaushalyaNo ratings yet
- One-Dimensional Kinematics: Physics 1401 Formula Sheet - Exam 3Document7 pagesOne-Dimensional Kinematics: Physics 1401 Formula Sheet - Exam 3Mia RismaliaNo ratings yet
- 2425 FormulasDocument2 pages2425 FormulassonuNo ratings yet
- Harmonic Oscillation, Komang SuardikaDocument125 pagesHarmonic Oscillation, Komang SuardikaKomang SuardikaNo ratings yet
- Lecture 22: Continuous Time Markov ChainsDocument5 pagesLecture 22: Continuous Time Markov ChainsspitzersglareNo ratings yet
- Introduction To ROBOTICS: ControlDocument15 pagesIntroduction To ROBOTICS: ControlMANOJ MNo ratings yet
- Lecture4 Quantum PythonDocument23 pagesLecture4 Quantum PythonSamNo ratings yet
- MPC ConceptsDocument26 pagesMPC Conceptsabdul_moiz_26No ratings yet
- Intensive ClassDocument163 pagesIntensive ClassJieqian Zhang100% (2)
- Quantum PhysicsDocument17 pagesQuantum PhysicsAgnivesh SharmaNo ratings yet
- Mathematical Modeling of Mechanical Systems and Electrical SystemsDocument49 pagesMathematical Modeling of Mechanical Systems and Electrical SystemsMary DunhamNo ratings yet
- Controller Design of Inverted Pendulum Using Pole Placement and LQRDocument7 pagesController Design of Inverted Pendulum Using Pole Placement and LQRInternational Journal of Research in Engineering and Technology100% (1)
- Mathematic Modelling of Dynamic SYSTEMS Ch. 2Document31 pagesMathematic Modelling of Dynamic SYSTEMS Ch. 2Irtiza IshrakNo ratings yet
- Week1a ControlDocument73 pagesWeek1a Controlarunkumar SNo ratings yet
- ECE 422/522 Power System Operations & Planning/Power Systems Analysis II: 7 - Transient StabilityDocument35 pagesECE 422/522 Power System Operations & Planning/Power Systems Analysis II: 7 - Transient StabilityMohEladibNo ratings yet
- 1 SignalsDocument17 pages1 SignalsTingyang YUNo ratings yet
- Student Solutions Manual to Accompany Economic Dynamics in Discrete Time, second editionFrom EverandStudent Solutions Manual to Accompany Economic Dynamics in Discrete Time, second editionRating: 4.5 out of 5 stars4.5/5 (2)
- Green's Function Estimates for Lattice Schrödinger Operators and ApplicationsFrom EverandGreen's Function Estimates for Lattice Schrödinger Operators and ApplicationsNo ratings yet
- Latitude and Longitudes in GeodesyDocument6 pagesLatitude and Longitudes in GeodesyAbdo SaeedNo ratings yet
- EasyAutoPaper - CLASS 9 - PHYSICS - Chapter 180Document2 pagesEasyAutoPaper - CLASS 9 - PHYSICS - Chapter 180a.basheer089No ratings yet
- RESO Maths (Advance) Revision Dpp-6Document7 pagesRESO Maths (Advance) Revision Dpp-6VyomNo ratings yet
- Right Triangle TrigDocument13 pagesRight Triangle TrigFranklin BuisaNo ratings yet
- Pensum Edu MathematicsDocument3 pagesPensum Edu MathematicsScribdTranslationsNo ratings yet
- 7 Gears: 7.1 Gear ClassificationDocument15 pages7 Gears: 7.1 Gear ClassificationSimrit Kaur MakanNo ratings yet
- Topic 3 - TrigonometryDocument10 pagesTopic 3 - Trigonometryapi-25887606100% (1)
- MSC Patran Nastran Student TutorialDocument72 pagesMSC Patran Nastran Student TutorialcardusansilniNo ratings yet
- ICSE Class 10 Maths Sample Paper 2 2021Document7 pagesICSE Class 10 Maths Sample Paper 2 2021Reet KhimavatNo ratings yet
- Topics in Algebra Solution: Sung Jong Lee, Lovekrand - Github.io December 5, 2020Document5 pagesTopics in Algebra Solution: Sung Jong Lee, Lovekrand - Github.io December 5, 2020VigneshNo ratings yet
- SPM Seminar 2017 Part 1 - Add Maths NotesDocument37 pagesSPM Seminar 2017 Part 1 - Add Maths NotesJoyce Lim100% (1)
- Sample Question Paper-Mid TermDocument1 pageSample Question Paper-Mid Termtrash emailNo ratings yet
- Five Trigonometry Identities ProblemsDocument2 pagesFive Trigonometry Identities ProblemsdibyanshuNo ratings yet
- 14a A Level Mathematics Practice Paper N - Pure MathematicsDocument5 pages14a A Level Mathematics Practice Paper N - Pure Mathematicssladha794No ratings yet
- EGD Sheet - 5Document2 pagesEGD Sheet - 5HARSHAL PAREKHNo ratings yet
- Mathematics: Quarter IV - Module 3Document18 pagesMathematics: Quarter IV - Module 3Marian IntalNo ratings yet
- Trigonometry - Question PaperDocument7 pagesTrigonometry - Question PaperAdavan BhavyNo ratings yet
- SLHJJT SMDocument14 pagesSLHJJT SMNick JaraNo ratings yet
- Hsslive-11. THREE DIMENSIONAL GEOMETRY PDFDocument7 pagesHsslive-11. THREE DIMENSIONAL GEOMETRY PDFTeam Electrical inspectorNo ratings yet
- Mvanginkel Radonandhough tr2004Document11 pagesMvanginkel Radonandhough tr2004Musadiq HussainNo ratings yet
- Chapter 5: Applications of Integration: Vietnam National Universities at Ho Chi Minh City International UniversityDocument48 pagesChapter 5: Applications of Integration: Vietnam National Universities at Ho Chi Minh City International UniversityKensleyTsangNo ratings yet
- Class 12th Maths Chapter 6 (Application of Derivates) UnsolvedDocument6 pagesClass 12th Maths Chapter 6 (Application of Derivates) Unsolvedmanoj DocsNo ratings yet
- What Is Atomic Packing Factor (And How To Calculate It For SC, BCC, FCC, and HCP) - Materials Science & EngineeringDocument1 pageWhat Is Atomic Packing Factor (And How To Calculate It For SC, BCC, FCC, and HCP) - Materials Science & EngineeringHIMANSHU SOMKUWARNo ratings yet
- Static Stability of Floating Structures PDFDocument84 pagesStatic Stability of Floating Structures PDFparamarthasom1974No ratings yet
- Transformation Between The International Terrestrial Refer-Ence System and The Geocentric Celestial Reference SystemDocument36 pagesTransformation Between The International Terrestrial Refer-Ence System and The Geocentric Celestial Reference SystemchandramaulisNo ratings yet
- Answers: Exercise 1.1Document22 pagesAnswers: Exercise 1.1aeroacademicNo ratings yet
- Trigonometry - How To Expand $ - Cos NX$ With $ - Cos X$ - Mathematics Stack ExchangeDocument5 pagesTrigonometry - How To Expand $ - Cos NX$ With $ - Cos X$ - Mathematics Stack Exchangetizio caglioNo ratings yet
- Unit-5 3D Transformation & Viewing: 2160703 Computer GraphicsDocument71 pagesUnit-5 3D Transformation & Viewing: 2160703 Computer GraphicsUzma Rukhayya ShaikNo ratings yet