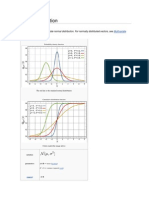
Standar Deviasi
Standar Deviasi
Download as pptx, pdf, or txt
You might also like
- Cu p2 Statistical Analysis Om PatelDocument7 pagesCu p2 Statistical Analysis Om PatelomNo ratings yet
- New Microsoft Office Word DocumentDocument941 pagesNew Microsoft Office Word DocumentPriya VenugopalNo ratings yet
- A Quick Approach To Statistics by G.R.pashADocument210 pagesA Quick Approach To Statistics by G.R.pashAAshfaq Khan75% (12)
- Medical Statistics and Demography Made Easy®Document353 pagesMedical Statistics and Demography Made Easy®Dareen Seleem100% (1)
- Biostatistics For Academic2Document38 pagesBiostatistics For Academic2Semo gh28No ratings yet
- Virtual University of Pakistan: Lecture No. 11Document39 pagesVirtual University of Pakistan: Lecture No. 11Atif KhanNo ratings yet
- Descriptive Statistics For Hicm UndergraduateDocument18 pagesDescriptive Statistics For Hicm UndergraduateThelma FortuNo ratings yet
- Measures of VariabilityADocument19 pagesMeasures of VariabilityAcaileyandrea19No ratings yet
- Measures of DispersionDocument32 pagesMeasures of DispersionShahmeerNo ratings yet
- Measures of DispersionDocument13 pagesMeasures of Dispersionsabnira AfrinNo ratings yet
- Dispersion 1Document32 pagesDispersion 1Karishma ChaudharyNo ratings yet
- Variance and Standard DeviationDocument4 pagesVariance and Standard Deviationapi-150547803No ratings yet
- Standard Deviation - Wikipedia, The Free EncyclopediaDocument12 pagesStandard Deviation - Wikipedia, The Free EncyclopediaManoj BorahNo ratings yet
- ShapesDocument36 pagesShapesaue.ponytoyNo ratings yet
- 2.2 Unit-DspDocument63 pages2.2 Unit-Dspsuryashiva422No ratings yet
- Stats and Prob Reviewer, Q3 Jess Anch.Document8 pagesStats and Prob Reviewer, Q3 Jess Anch.JessicaNo ratings yet
- Mohan MathsDocument16 pagesMohan Mathsmohan75xNo ratings yet
- الفصل الثاني الاحصاءDocument27 pagesالفصل الثاني الاحصاءbifusk481No ratings yet
- Chapter 5 Measures of DispersionDocument31 pagesChapter 5 Measures of Dispersionhanageenyo99No ratings yet
- IntroBioInfStatistics - Chapter2.revised 8956517989503105Document28 pagesIntroBioInfStatistics - Chapter2.revised 8956517989503105Edn Ed EddieNo ratings yet
- Chapter 4Document48 pagesChapter 4alex tomsonNo ratings yet
- Chapter 4 Measures of DispersionDocument45 pagesChapter 4 Measures of Dispersionmonicabalamurugan27No ratings yet
- 23006026_NUR HAMNI_TASK 7 STAT. DESKRIPTIF englishDocument10 pages23006026_NUR HAMNI_TASK 7 STAT. DESKRIPTIF englishnurhamni35No ratings yet
- Chapter-3ni Kamote ChuaDocument29 pagesChapter-3ni Kamote ChuaBryan GonzalesNo ratings yet
- Mathematics Statistical Square Root Mean SquaresDocument5 pagesMathematics Statistical Square Root Mean SquaresLaura TaritaNo ratings yet
- Last Formuas of First ChapterDocument20 pagesLast Formuas of First ChapterBharghav RoyNo ratings yet
- Measures of Variability GROUPED DATADocument13 pagesMeasures of Variability GROUPED DATAtojiflms100% (1)
- Mean, MedianDocument26 pagesMean, MedianAliNurRahmanNo ratings yet
- Standard Deviation-From WikipediaDocument11 pagesStandard Deviation-From WikipediaahmadNo ratings yet
- MAT2001-Statistics For Engineers: Measures of VariationDocument22 pagesMAT2001-Statistics For Engineers: Measures of VariationBharghav RoyNo ratings yet
- Measures of DispersionDocument3 pagesMeasures of DispersionAbrar AhmadNo ratings yet
- StatestsDocument20 pagesStatestskebakaone marumoNo ratings yet
- Measures of Dispersion TendencyDocument7 pagesMeasures of Dispersion Tendencyashraf helmyNo ratings yet
- Standerd DiviationDocument14 pagesStanderd DiviationPrageeth Nalaka ArambegedaraNo ratings yet
- Chapter 4Document46 pagesChapter 4Javeria NaseemNo ratings yet
- Laguna State Polytechnic University: Professor: Dr. Lucita G. Subillaga Reporter: Jean Paul V. Banay - M.A.Ed. - E.MDocument4 pagesLaguna State Polytechnic University: Professor: Dr. Lucita G. Subillaga Reporter: Jean Paul V. Banay - M.A.Ed. - E.MRyan Paul NaybaNo ratings yet
- Measure VariabilityDocument6 pagesMeasure VariabilityAlexander DacumosNo ratings yet
- Chapter 4-1Document46 pagesChapter 4-1Shahzaib SalmanNo ratings yet
- Chapter 4Document8 pagesChapter 4NJeric Ligeralde AresNo ratings yet
- Haseeb Akbar 37 Statistics AssignmentDocument45 pagesHaseeb Akbar 37 Statistics AssignmentHaseeb AkbarNo ratings yet
- Theory of Uncertainty of Measurement PDFDocument14 pagesTheory of Uncertainty of Measurement PDFLong Nguyễn VănNo ratings yet
- Absolute Measure of DispersionDocument4 pagesAbsolute Measure of DispersionMuhammad ImdadullahNo ratings yet
- Univariate StatisticsDocument4 pagesUnivariate StatisticsDebmalya DuttaNo ratings yet
- The Scalar Algebra of Means, Covariances, and CorrelationsDocument21 pagesThe Scalar Algebra of Means, Covariances, and CorrelationsOmid ApNo ratings yet
- Measures of Dispersion - Range, Deviation and Variance With ExamplesDocument14 pagesMeasures of Dispersion - Range, Deviation and Variance With ExamplesDCNo ratings yet
- Dispersion: Handout #7Document6 pagesDispersion: Handout #7Bonaventure NzeyimanaNo ratings yet
- Measure of dispersionDocument2 pagesMeasure of dispersionariffuad38No ratings yet
- Chapter 5_Measures of VariabilityDocument35 pagesChapter 5_Measures of VariabilityANo ratings yet
- 3median - WikipediaDocument44 pages3median - WikipediajlesalvadorNo ratings yet
- Variance and Standard DeviationDocument15 pagesVariance and Standard DeviationSrikirupa V Muraly100% (3)
- Measures of Dispersion - 1Document44 pagesMeasures of Dispersion - 1muhardi jayaNo ratings yet
- Chap2 Numerical Summary Measures UploadDocument54 pagesChap2 Numerical Summary Measures Uploadbảo thếNo ratings yet
- Summary Statistics, Distributions of Sums and Means: Joe FelsensteinDocument21 pagesSummary Statistics, Distributions of Sums and Means: Joe FelsensteinmhdstatNo ratings yet
- technical-analysis-PDFdrive-10Document17 pagestechnical-analysis-PDFdrive-1020mayis20No ratings yet
- Class Notes v1Document4 pagesClass Notes v1Parvat ChavhanNo ratings yet
- Statistic and ProbabilityDocument15 pagesStatistic and ProbabilityFerly TaburadaNo ratings yet
- BBBDocument9 pagesBBBchxrlslxrrenNo ratings yet
- MCT Biost FuoDocument10 pagesMCT Biost Fuofelixebikonbowei2022No ratings yet
- (213805375) DispersionDocument49 pages(213805375) DispersionshahjafferNo ratings yet
- Measures of VariationDocument30 pagesMeasures of VariationJahbie ReyesNo ratings yet
- Student's Solutions Manual and Supplementary Materials for Econometric Analysis of Cross Section and Panel Data, second editionFrom EverandStudent's Solutions Manual and Supplementary Materials for Econometric Analysis of Cross Section and Panel Data, second editionNo ratings yet
- Measures of VariabilityDocument21 pagesMeasures of VariabilitybeckonashiNo ratings yet
- 11 Stat 6 Measures of DispersionDocument17 pages11 Stat 6 Measures of Dispersioneco protectionNo ratings yet
- Chapter 4&5Document33 pagesChapter 4&5Geez DesignNo ratings yet
- Decision ScienceDocument9 pagesDecision ScienceSourav SaraswatNo ratings yet
- Lesson 10 Measures of Variability - Grouped Data High SchoolDocument13 pagesLesson 10 Measures of Variability - Grouped Data High SchoolAlbec Sagrado Ballacar100% (1)
- Detailed Lesson Plan in Mathematics 8Document7 pagesDetailed Lesson Plan in Mathematics 8Leon MathewNo ratings yet
- Operations Management Chapter 3Document37 pagesOperations Management Chapter 3Tina Dulla67% (3)
- Mean Median Mode PDFDocument52 pagesMean Median Mode PDFSunpreet Kaur NandaNo ratings yet
- 405d - Business StatisticsDocument21 pages405d - Business StatisticsSaurabh AdakNo ratings yet
- Mean Deviation Problems PDFDocument10 pagesMean Deviation Problems PDFRaghavendra JeevaNo ratings yet
- Lecture No 9Document24 pagesLecture No 9Wra ArirmiwniNo ratings yet
- NCERT Solutions For Class 11 Maths Chapter - 15 StatisticsDocument6 pagesNCERT Solutions For Class 11 Maths Chapter - 15 StatisticsMukund YadavNo ratings yet
- Measure of Dispersion (Range Quartile & Mean Deviation)Document55 pagesMeasure of Dispersion (Range Quartile & Mean Deviation)Wasie UrrahmanNo ratings yet
- Maths 2A SeniorDocument14 pagesMaths 2A SeniorARAVIND ARV7733% (3)
- Measures of Dispersion (Unit1)Document36 pagesMeasures of Dispersion (Unit1)Rishab Jain 2027203100% (1)
- Exemplar Distance Learning LessonDocument4 pagesExemplar Distance Learning Lessonapi-636150180No ratings yet
- Qtns On MGTDocument28 pagesQtns On MGTSamuela Baby-Naa AttuquayefioNo ratings yet
- Central Tendency and VariabilityDocument20 pagesCentral Tendency and VariabilityAli AkbarNo ratings yet
- GE 7 Module 4Document33 pagesGE 7 Module 4Emmanuel DalioanNo ratings yet
- Lecture 6 - Measures of VariabilityDocument3 pagesLecture 6 - Measures of VariabilityRae WorksNo ratings yet
- Topic: Measures of Dispersion (Test 1) : Type Questions Get Answers MCQ Quiz Online English Objective Test MCQ TestDocument2 pagesTopic: Measures of Dispersion (Test 1) : Type Questions Get Answers MCQ Quiz Online English Objective Test MCQ Testzaheer abbasNo ratings yet
- CHAPTER5 Assessment AnswerDocument20 pagesCHAPTER5 Assessment AnswerJulius BalbinNo ratings yet
- Chapter - 4 DispersionDocument10 pagesChapter - 4 DispersionKishan GuptaNo ratings yet
- Chapter-11 Measures of Dispersion: Class XIDocument30 pagesChapter-11 Measures of Dispersion: Class XIcheshaNo ratings yet
- NMDocument18 pagesNMAmrinderpal SinghNo ratings yet
- Average DeviationDocument2 pagesAverage DeviationRandom Bll ShTNo ratings yet
- UNIT IV Dispersion and SkewnessDocument12 pagesUNIT IV Dispersion and SkewnessVidhya BNo ratings yet