
More Related Content
Similar to How to assign unowned disk in the netapp cluster 8.3
Similar to How to assign unowned disk in the netapp cluster 8.3 (20)
More from Saroj Sahu
More from Saroj Sahu (20)
Recently uploaded
Recently uploaded (20)
How to assign unowned disk in the netapp cluster 8.3
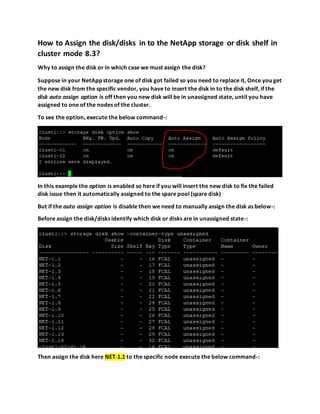
- 1. How to Assign the disk/disks in to the NetApp storage or disk shelf in cluster mode 8.3? Why to assign the disk or in which case we must assign the disk? Suppose in your NetApp storage one of disk got failed so you need to replace it, Once you get the new disk from the specific vendor, you have to insert the disk in to the disk shelf, if the disk auto assign option is off then you new disk will be in unassigned state, until you have assigned to one of the nodes of the cluster. To see the option, execute the below command-: In this example the option is enabled so here if you will insert the new disk to fix the failed disk issue then it automatically assigned to the spare pool (spare disk) But if the auto assign option is disable then we need to manually assign the disk as below-: Before assign the disk/disks identify which disk or disks are in unassigned state-: Then assign the disk here NET-1.1 to the specific node execute the below command-:
- 2. The disk NET-1.1 has been assigned to the node clust1-01 To see the owner of the disk, execute the below command-: The disk is owned by the node clust1-01 If you want to set up automatic ownership assignment at the stack or shelf level. The above command * (star) indicates on all nodes in the cluster. Now, all the nodes are enabled with the auto assign of the disks Configure automatic ownership assignment at the shelf level-: Configure automatic turn off ownership assignment of the disks in the shelf level
- 3. Note-:You have the disk shelf whose disks are owned by one node and another shelf on the same loop who disks are owned by different nodes then in this case you need to configure automatic disk ownership at the shelf level for all the node in the cluster. Thank you!! Saroj Senior Storage Specialist (NCDA and AWS Certified)