データ構造
【英】:data structure
概要
与えられたデータを, 計算の高速化のために構造をもたせて記憶する手法の総称. 目的に合わせ, あるいくつかの機能を, 高速, あるいは省メモリで行えるよう設計される. 例えば, ある言葉を 個の言葉の辞書データから検索するとき, 通常の配列では, 最悪で挿入・削除に
個の言葉の辞書データから検索するとき, 通常の配列では, 最悪で挿入・削除に  , 検索に
, 検索に 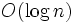 か, 挿入と削除に
か, 挿入と削除に  , 検索に の時間を要する. 二分探索木というデータ構造は, これらの機能を 時間で行い, 使用メモリは である.
, 検索に の時間を要する. 二分探索木というデータ構造は, これらの機能を 時間で行い, 使用メモリは である.
詳説
データ構造とは, 与えられたデータに対して, そのデータを使った計算の高速化, そのデータを記憶するために必要な領域の減少等の目的で, データに構造を持たせ, データに対する操作の効率化を行う手法の総称である. あるいくつかの機能を, データの記憶形式と, その形式のデータを操作するアルゴリズムにより実現する.
通常のコンピューター言語では, データを蓄える手法として配列かリスト, またはその両方が用意されている. 配列は指定した位置にあるデータに 時間でアクセスでき, リストは与えられたデータを並べて記憶し, 隣のデータに時間でアクセスできる. リストは配列により実現可能だが, リストで配列は実現できない.
時間でアクセスでき, リストは与えられたデータを並べて記憶し, 隣のデータに時間でアクセスできる. リストは配列により実現可能だが, リストで配列は実現できない.
配列やリストは最も単純なデータ構造である. ここで両者を使ったデータ構造の性能の違いを見てみよう. 例として 行 列の行列 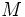 を保持し, 他の行列との掛け算を行うためのデータ構造を考える. 通常の配列を使用して行列を記憶する場合
を保持し, 他の行列との掛け算を行うためのデータ構造を考える. 通常の配列を使用して行列を記憶する場合  のメモリが必要であるが, もし の非零要素の数
のメモリが必要であるが, もし の非零要素の数  が小さい場合, 非零要素を連結してリストで持つことにより, 記憶容量を
が小さい場合, 非零要素を連結してリストで持つことにより, 記憶容量を  まで減少させることができる. 行列の掛け算は非零要素に関する部分だけ計算を行えばよいので, 計算時間も2つの行列の非零要素の数の積に比例する. しかし, リストは一要素を記憶するのに必要なメモリが配列に比べて大きいので, 非零要素が多い場合はリストのほうが遅く, メモリも多くなる.
まで減少させることができる. 行列の掛け算は非零要素に関する部分だけ計算を行えばよいので, 計算時間も2つの行列の非零要素の数の積に比例する. しかし, リストは一要素を記憶するのに必要なメモリが配列に比べて大きいので, 非零要素が多い場合はリストのほうが遅く, メモリも多くなる.
次に, 個の用語の辞書データを保持し, その中から与えられた用語を検索するためのデータ構造を考える. データに変更がないときは, 用語を辞書順で並べて記憶すれば, 二分探索により 時間で1つの用語が検索できる. しかし, 辞書データの中の用語を削除する・新しい用語を追加する, という操作が必要な場合には, 通常平均的に
時間で1つの用語が検索できる. しかし, 辞書データの中の用語を削除する・新しい用語を追加する, という操作が必要な場合には, 通常平均的に の時間を要する. 辞書順に並べるかわりに, 二分探索木 (AVL木, 2-3木など) というデータ構造を用いれば, 使用メモリはのままで, これらの操作の実行時間をまで減らすことができる. このようにデータの動的な変化に対しても効率が良く操作が行えるよう設計されたデータ構造を動的データ構造という. 辞書データを扱う他の効率の良いデータ構造としてはハッシュ表が知られている.
の時間を要する. 辞書順に並べるかわりに, 二分探索木 (AVL木, 2-3木など) というデータ構造を用いれば, 使用メモリはのままで, これらの操作の実行時間をまで減らすことができる. このようにデータの動的な変化に対しても効率が良く操作が行えるよう設計されたデータ構造を動的データ構造という. 辞書データを扱う他の効率の良いデータ構造としてはハッシュ表が知られている.
動的データ構造の中で最も基礎的なものとしてはヒープが挙げられる. 基本的なヒープは, 個の要素の中の最小値を得る・要素の追加・削除するという操作を, 1回あたり時間で実行し, またメモリ使用量もである. 応用も広く, プリム法 (最小木問題のアルゴリズム), 最少費用フロー問題 (最小費用流問題) のアルゴリズムなどで使用される. また, 改良版の Fヒープ (フィボナッチヒープ) は, 最短路問題を解くアルゴリズムで使われている. その他, 個の区間の集合を保持し, 質問点を含む区間を列挙する, 区間の挿入・削除を行う, などの操作を1回あたり 時間で行う区分木, 大きさ の木構造のグラフに対し, 合併・分割・変形・ある頂点の子孫数を求める, など多くの操作を時間で行う動的木, 集合の合併と要素の探索を高速化し, 回の合併と  回の探索の合計時間がほぼ
回の探索の合計時間がほぼ  となる集合ユニオン・ファインド木, 動的に変化する有向グラフの強連結性を保持し,
となる集合ユニオン・ファインド木, 動的に変化する有向グラフの強連結性を保持し,  回の枝の挿入・削除を
回の枝の挿入・削除を  で行うデータ構造[7], など数多くのものが考案されている. 文字列やグラフを扱う離散アルゴリズムの多くは, これらの基礎的なデータ構造に手を加えたものを使用することにより高速化されている. また, アルゴリズムの動作記録を変換して保持し, パラメーターの変更による計算結果の変化を出力するデータ構造は動的計画, 組み合わせ最適化問題の感度分析などに応用が広い.
で行うデータ構造[7], など数多くのものが考案されている. 文字列やグラフを扱う離散アルゴリズムの多くは, これらの基礎的なデータ構造に手を加えたものを使用することにより高速化されている. また, アルゴリズムの動作記録を変換して保持し, パラメーターの変更による計算結果の変化を出力するデータ構造は動的計画, 組み合わせ最適化問題の感度分析などに応用が広い.
データ構造, 特に動的データ構造は, 計算幾何学における発展が著しい. 幾何的なデータはデータの量に対して構造が複雑なものが多い. 例えば, 平面上の 点の集合に対し, 距離が  以下の2点を枝でつないだグラフ(幾何グラフ)を考える. このグラフは
以下の2点を枝でつないだグラフ(幾何グラフ)を考える. このグラフは  本の枝を含む可能性があるが, このグラフを記憶するには点集合だけ記憶すれば十分である. つまり, メモリや計算時間を省略するためには, 点集合のデータから必要な枝の情報を得るための構造が必要となる. また, 枝の交差など, グラフ的な情報からは導けないものもあり, それらの情報を効率的に得るためにもデータ構造はかかせない. 幾何的なデータ構造としては, 平面上の点集合の凸包を保持し, 点の追加・消去に対し新しい凸包を 時間で求めるもの, 次元の 点集合に対し, 質問点から近い順に点を1個あたり平均 時間で出力する
本の枝を含む可能性があるが, このグラフを記憶するには点集合だけ記憶すれば十分である. つまり, メモリや計算時間を省略するためには, 点集合のデータから必要な枝の情報を得るための構造が必要となる. また, 枝の交差など, グラフ的な情報からは導けないものもあり, それらの情報を効率的に得るためにもデータ構造はかかせない. 幾何的なデータ構造としては, 平面上の点集合の凸包を保持し, 点の追加・消去に対し新しい凸包を 時間で求めるもの, 次元の 点集合に対し, 質問点から近い順に点を1個あたり平均 時間で出力する  木, 質問領域の中に含まれる点を1個あたり
木, 質問領域の中に含まれる点を1個あたり で出力するレンジサーチ木 [8], 平面をいくつかの領域に分割する 本の線分の集合が与えられたとき, 質問点がどの領域に含まれるかを 時間で答える領域探索などが挙げられる. その他に, 線分の集合に対し, ある点から見える点, すなわち2点をつなぐ線分が他の線分と交差しないような点集合を保持するデータ構造など, 交差, 領域に関してさまざまなデータ構造が考案されている.
で出力するレンジサーチ木 [8], 平面をいくつかの領域に分割する 本の線分の集合が与えられたとき, 質問点がどの領域に含まれるかを 時間で答える領域探索などが挙げられる. その他に, 線分の集合に対し, ある点から見える点, すなわち2点をつなぐ線分が他の線分と交差しないような点集合を保持するデータ構造など, 交差, 領域に関してさまざまなデータ構造が考案されている.
前述の幾何的なデータ構造は, 幾何的な対象を扱う計算幾何学のアルゴリズムで多く使われている. 多角形の三角形分割の線形時間アルゴリズムなども高度な技術を用いてデータ構造を活用しているが, しかしその反面複雑になりすぎ, 現実的ではないという欠点がある. また, 個々のアルゴリズムで使用するデータ構造がそのアルゴリズムに特化した, 一般性のないアルゴリズムとデータ構造も少なくない. それゆえ, 最近では簡素化も視野に入れた研究が進んでいる. スパーシフィケイション [6] もその一つであり, 動的データ構造高速化の一般化した技術を提供している. スパーシフィケーションにより, 頂点 枝を持つ無向グラフの最小全張木を保持するデータ構造は, 1回の枝の追加・削除・重みの変化に対する計算時間が,  から
から に高速化される. また同様にグラフの二部グラフ性の判定, 二連結性の判定, 頂点連結性の判定なども, 一回の操作の計算時間が
に高速化される. また同様にグラフの二部グラフ性の判定, 二連結性の判定, 頂点連結性の判定なども, 一回の操作の計算時間が  から に高速化される.
から に高速化される.
最後に参考文献を挙げる. 動的木などグラフ的なデータ構造は [3], [4], [5] 等に詳しい. また, 幾何的データ構造については [1], [2] 等が詳しい.
[1] F. P. Preparata and M. L. Shamos, "Computational Geometry - An Introduction," Springer-Verlag, 1985. 浅野孝夫, 浅野哲夫 訳,『計算幾何学入門』, 総研出版, 1992.
[2] 今井浩, 今井圭子,『計算幾何学』, 共立出版, 1994.
[3] T. H. Cormen, C. E. Leiserson and R. L. Rivest, "Introduction To Algorithms," The MIT Press, 1990. 浅野哲夫, 岩間和生, 梅尾博司, 山下雅史, 和田幸一 訳,『アルゴリズムイントロダクション 1,2,3巻』, 近代科学, 1995.
[4] 浅野孝夫,『情報の構造 上, 下』, 日本評論社, 1994.
[5] 茨木俊秀,『アルゴリズムとデータ構造』, 昭晃堂, 1989.
[6] D. Eppstein, Z. Galil, G. F. Italiano, A. Nissenzweig "Sparsification - A Technique for Speeding up Dynamic Graph Algorithms," FOCS, 33, 1992
[7] S. Khanna, R. Motwani and R. H. Wilson, "On Certificates and Lookahead in Dynamic Graph Problems," SODA, 1995
[8] D. E. Willard "New Data Structures for Orthogonal Range Queries," SIAM Journal on Computing, 14 (1985), 232-253.
データ構造
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2024/11/26 18:57 UTC 版)


データ構造(データこうぞう、英: data structure)とは、コンピュータプログラミングでの、データの集まりの形式化された構成である。格納された各データの参照や修正といった管理を容易にするための構成である[1][2][3][4][5]。一定の関係性を持たせたデータ型のコレクションであり、データ値に適用するための関数や手続きも格納されることがある[6]。データの代数的構造とも言われる。
概要
ソフトウェア開発において、データ構造についてどのような設計を行うかは、プログラム(アルゴリズム)の効率に大きく影響する。そのため、さまざまなデータ構造が考え出されている。多くのプログラムの設計において、データ構造の選択は主要な問題である。これは大規模システムの構築において、実装の困難さや質、最終的な性能は最良のデータ構造を選択したかどうかに大きく依存してきたという経験の結果である。
多くの場合、データ構造が決まれば、利用するアルゴリズムは比較的自明に決まる。しかし場合によっては、順番が逆になる。つまり、与えられた仕事をこなす最適なアルゴリズムを使うために、そのアルゴリズムが前提としている特定のデータ構造が選択される。いずれにしても適切なデータ構造の選択は極めて重要である。この洞察は、多くの定式化された設計手法やプログラミング言語において、データ構造がアルゴリズムよりも重要な構成要素とされていることにも現れている。現代的なプログラミング言語は異なるアプリケーションにおいてデータ構造の安全な再利用を可能とするように、実装の詳細をインターフェースの背後に隠蔽するための、モジュール化のしくみを備えている。C++やJavaなどのオブジェクト指向プログラミング言語はクラスをこの目的のために用いている。
データ構造は専門的な、あるいは非専門的な(すなわち、あらゆる)プログラミングにとって非常に重要なので、C++におけるSTLや、Java API、および.NET Frameworkのようなプログラミング言語の標準ライブラリや環境において多くのデータ構造が利用可能となっている。データ構造が実装を表すのかそれともインターフェースを表すのかについての議論は多少ある。どのように見えるのかは相対的な問題であるのかもしれない。データ構造は関数同士の間のインターフェイスとして見ることもできるし、データ型に基づいて構成されたストレージにアクセスする方法を実装したものとして見ることもできる。
基本的なデータ構造の例
- 配列
- リスト
- 木
- ファイル
- ハッシュ表
- 辞書
- 集合
- レコード
脚注
- ^ Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009). Introduction to Algorithms, Third Edition (3rd ed.). The MIT Press. ISBN 978-0262033848
- ^ Black, Paul E. (15 December 2004). “data structure”. In Pieterse, Vreda; Black, Paul E.. Dictionary of Algorithms and Data Structures [online]. National Institute of Standards and Technology 2018年11月6日閲覧。
- ^ "Data structure". Encyclopaedia Britannica. 17 April 2017. 2018年11月6日閲覧。
- ^ ゴンザロ・ナバロ:「コンパクトデータ構造 実践的アプローチ」、講談社サイエンティフィク、(2023年7月26日)、ISBN 978-4-06-512476-5
- ^ 定兼邦彦:「簡潔データ構造」、共立出版、ISBN 978-4-320-12174-4 (2018年2月25日)
- ^ Wegner, Peter; Reilly, Edwin D. (2003-08-29). Encyclopedia of Computer Science. Chichester, UK: John Wiley and Sons. pp. 507–512. ISBN 978-0470864128
関連項目
データ構造
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2018/07/22 02:07 UTC 版)
一般に、ライフゲームの(理論上の)フィールドは無限に広い格子である。扱いやすさなどのために、多くの場合、その格子点に縦横に整数で付番し、原点すなわち (0, 0) の近くに有限個の「生存」セルによるパターンがあるものとし、残りの無限の部分を無限個の非生存のセルとする。以上は理論的な観点からの話だが、実装では、生存しているセルがある付近を十分にカバーできる情報があれば良い。 ハッシュライフでは、1辺が2の冪乗個のセルの正方形の領域を、縦横それぞれ2等分する四分木構造の再帰でフィールドを表現する。この時、その範囲内のフィールドの状態にもとづくハッシュ値をキーにしたハッシュテーブルを併用し、全く同じ状態のフィールドであれば、四分木構造における部分木を共有する(すなわち、実際には木ではなくDAGとなっている)。このようなハッシュ(ハッシュテーブル)を利用した効率化を図るものであることから、その名がある。 一般的なライフゲームのアプリケーションソフトのエンジンとして利用するには、全盤面の1世代後を得る手続きも実装する必要もあるが、少々煩雑な部分があるのでここでは省略する。以下で述べる高速化についても、概要のみとする。 ここで、木の深さ0で一辺が1セルとする。規則的で再帰的な四分木構造により、深さ1では一辺が2セルの正方形、深さ2では一辺が4セル……というようにして、深さkの木は一辺が2k個のセルからなる22k個のセルの正方形をあらわしている(前述のように具体的にはDAGで実装する)。周辺との干渉があるから、「その領域全体の未来の状態」のメモ化は不可能である。1辺が4セルの時、その中央の2x2の領域の1世代先の状態については確定的なのでメモ化できる。そして、8x8の領域に対しては中心4x4の領域の2世代先の状態、16x16の領域に対しては中心8x8の領域の4世代先の状態というように、倍々で、より未来の世代のメモ化が可能であり、また、効率的に計算することもできるというのが急所である。一般に、木の深さkで、中心にある2k-1x2k-1個のセルの正方形の領域の2k-2世代先をメモ化できる。この「メモ」の範囲とその未来の世代は、ライフゲームの「光速」によって、その世代における結果は確定的であることから、うまく機能するということが言える。ハッシュライフの著しい利点として、このメモ化の利用により、例えば動作が数万世代を超えるような巨大なパターンについて、何世代もスキップさせつつ、その後の結果のみを迅速に得ることができる。
※この「データ構造」の解説は、「ハッシュライフ」の解説の一部です。
「データ構造」を含む「ハッシュライフ」の記事については、「ハッシュライフ」の概要を参照ください。
「データ構造」の例文・使い方・用例・文例
データ構造と同じ種類の言葉
固有名詞の分類
- データ構造のページへのリンク


