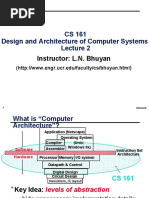
Instructions: Language of The Computer: Omputer Rganization and Esign
Instructions: Language of The Computer: Omputer Rganization and Esign
Download as pdf or txt
You might also like
- Chapter 02 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionDocument93 pagesChapter 02 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionPriyanka Meena75% (4)
- Chapter 2 Instructions Language of The ComputerDocument95 pagesChapter 2 Instructions Language of The Computerq qqNo ratings yet
- Assembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageFrom EverandAssembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageRating: 5 out of 5 stars5/5 (2)
- Template Resource MobilizationDocument7 pagesTemplate Resource Mobilizationtelteguh33% (3)
- Instructions: Language of The Computer: Omputer Rganization and EsignDocument33 pagesInstructions: Language of The Computer: Omputer Rganization and EsignBody AbdoNo ratings yet
- CA 05 InstructionsDocument35 pagesCA 05 InstructionsC-typeNo ratings yet
- Week4 InstructionsDocument36 pagesWeek4 InstructionsAfs AsgNo ratings yet
- L3 - Assembly & ISA - (Ch2) - IDocument20 pagesL3 - Assembly & ISA - (Ch2) - IbreaducNo ratings yet
- פרק ד - אסמבליDocument176 pagesפרק ד - אסמבליWeiß KatzeNo ratings yet
- Lecture 4 - Instructions Language of The Computer IIDocument27 pagesLecture 4 - Instructions Language of The Computer IIXrsamixNo ratings yet
- Instructions: Language of The Computer: Omputer Rganization and EsignDocument31 pagesInstructions: Language of The Computer: Omputer Rganization and EsignBody AbdoNo ratings yet
- Chapter 02Document112 pagesChapter 02Yassine BlaliNo ratings yet
- lect2Document54 pageslect2sounaksantra4No ratings yet
- Lecture 3Document14 pagesLecture 3zeinaakhaled1No ratings yet
- L3 - Assembly & ISA - (Ch2) - IIDocument27 pagesL3 - Assembly & ISA - (Ch2) - IIbreaducNo ratings yet
- Instructions: Language of The Computer: The Hardware/Software Interface 5Document54 pagesInstructions: Language of The Computer: The Hardware/Software Interface 5ritikNo ratings yet
- Instructions: Language of The Computer: The Hardware/Software Interface 5Document68 pagesInstructions: Language of The Computer: The Hardware/Software Interface 5RANDOM KUMARNo ratings yet
- Instructions: Language of The Computer PDocument92 pagesInstructions: Language of The Computer PAdip ChyNo ratings yet
- Chapter 02 RISC VDocument95 pagesChapter 02 RISC VAliosaNo ratings yet
- Chapter 02 Computer Organization and Design Fifth Edition The Hardware Software Interface The Morgan Kaufmann Series in Computer Architecture and DDocument93 pagesChapter 02 Computer Organization and Design Fifth Edition The Hardware Software Interface The Morgan Kaufmann Series in Computer Architecture and DParth PadiaNo ratings yet
- Chapter 02Document94 pagesChapter 02mostafayounis630No ratings yet
- Instructions: Language of The ComputerDocument92 pagesInstructions: Language of The Computerdelinquent_abhishekNo ratings yet
- Chapter 2:instructions: Language of The ComputerDocument81 pagesChapter 2:instructions: Language of The ComputerGreen ChiquitaNo ratings yet
- Chapter 2 Instructions Language of The ComputerDocument93 pagesChapter 2 Instructions Language of The ComputersonygabrielNo ratings yet
- Instructions: Language of The Computer: Computer Organization and DesignDocument99 pagesInstructions: Language of The Computer: Computer Organization and DesignArvind RameshNo ratings yet
- Chapter 2 Instructions Language of The ComputerDocument94 pagesChapter 2 Instructions Language of The Computerkrishnagovind33No ratings yet
- Mips PPT SlidesDocument35 pagesMips PPT SlidesHassanMalikNo ratings yet
- Tema 2 GII EC Lenguaje Ensamblador Latest PDFDocument88 pagesTema 2 GII EC Lenguaje Ensamblador Latest PDFJorge ArmasNo ratings yet
- Instructions: Language of The Computer: The Hardware/Software Interface 5Document76 pagesInstructions: Language of The Computer: The Hardware/Software Interface 5Sara AlkheilNo ratings yet
- Lecture 4Document16 pagesLecture 4zeinaakhaled1No ratings yet
- Lecture 4 - Instructions Language of The Computer IIDocument27 pagesLecture 4 - Instructions Language of The Computer IIXrsamixNo ratings yet
- Fall 2019 - Assembly ProgrammingDocument50 pagesFall 2019 - Assembly ProgrammingPooja VashisthNo ratings yet
- Chapter 02 RISC VDocument92 pagesChapter 02 RISC VPushkal MishraNo ratings yet
- Chapter 02Document91 pagesChapter 02Valentino Oliva FunesNo ratings yet
- Instructions: Language of The Computer: Dr. Randa MohamedDocument21 pagesInstructions: Language of The Computer: Dr. Randa MohamedBody AbdoNo ratings yet
- Chapter 02-JadaraDocument64 pagesChapter 02-Jadarakaled20188aNo ratings yet
- Lecture 3Document43 pagesLecture 3Muntasir SunnyNo ratings yet
- Chapter 02Document90 pagesChapter 02deepaknittrichyNo ratings yet
- 11 Risc Cisc and Assemblers IDocument39 pages11 Risc Cisc and Assemblers Ictfemylive123No ratings yet
- L2 Instructions Language of The ComputerDocument21 pagesL2 Instructions Language of The ComputerMD Shakil SickderNo ratings yet
- Instructions: Language of The MachineDocument157 pagesInstructions: Language of The Machinenshayan81No ratings yet
- Chapter 0siuhdsauidiuDocument56 pagesChapter 0siuhdsauidiuAbubakar sabirNo ratings yet
- Mips Assembly SummaryDocument56 pagesMips Assembly SummaryJenn AguilarNo ratings yet
- CS2100 Computer Organisation: MIPS ProgrammingDocument175 pagesCS2100 Computer Organisation: MIPS ProgrammingamandaNo ratings yet
- Mips IsaDocument19 pagesMips IsaHritwik GhoshNo ratings yet
- 2 - Mips IsaDocument22 pages2 - Mips IsaxuanzzkNo ratings yet
- Data Structures & Algorithms - Topic 2 - Primitive Data Structures (1)Document60 pagesData Structures & Algorithms - Topic 2 - Primitive Data Structures (1)arsalanbaig099No ratings yet
- Instructions Language of The ComputerDocument93 pagesInstructions Language of The ComputerRachasak RagkamnerdNo ratings yet
- ch2 PDFDocument66 pagesch2 PDFYousef MomaniNo ratings yet
- Lectures 3-4: MIPS Instructions: MotivationDocument22 pagesLectures 3-4: MIPS Instructions: Motivationbilo044No ratings yet
- CA Chap2 Isa Nlt2020Document58 pagesCA Chap2 Isa Nlt2020imagoodboy0703No ratings yet
- 2 Isa cs161f16Document109 pages2 Isa cs161f16Van Thi Muoi Ngoc NgocNo ratings yet
- 07-08 - CO - B2Ch2 - MIPS Instruction SetDocument62 pages07-08 - CO - B2Ch2 - MIPS Instruction SetSeif RedaNo ratings yet
- Week 2 - Instructions Language of The Computer - Part 1Document94 pagesWeek 2 - Instructions Language of The Computer - Part 1Maycol FFNo ratings yet
- ARM Computer Organization-Chapter02Document91 pagesARM Computer Organization-Chapter02doviva8391No ratings yet
- 02a MIPSassemblyDocument26 pages02a MIPSassemblyJulian RamosNo ratings yet
- LECTURE2Document26 pagesLECTURE2Ahmed MahjoubNo ratings yet
- Week 4 - Lecture 4 - MIPS ISADocument38 pagesWeek 4 - Lecture 4 - MIPS ISAkhoản 1 tàiNo ratings yet
- Mega Drive Architecture: Architecture of Consoles: A Practical Analysis, #3From EverandMega Drive Architecture: Architecture of Consoles: A Practical Analysis, #3No ratings yet
- Primark Case Study: Ergo Managed Print ServicesDocument2 pagesPrimark Case Study: Ergo Managed Print ServicesDwitya AribawaNo ratings yet
- MIS ClassificationDocument25 pagesMIS Classificationanahad VaidyaNo ratings yet
- Ficha Kit 4 Camaras NG V400Document3 pagesFicha Kit 4 Camaras NG V400jpalbetobtcNo ratings yet
- Dokumen - Tips - Building A Flexible Ui With Oracle ApexDocument40 pagesDokumen - Tips - Building A Flexible Ui With Oracle ApexAlaa Eldeen M ANo ratings yet
- Smart Project ManagementDocument73 pagesSmart Project ManagementDr P AdhikaryNo ratings yet
- Weigh Bridge Check List Final March 24Document1 pageWeigh Bridge Check List Final March 24happ_dentNo ratings yet
- Excel Vba Search PDF FilesDocument2 pagesExcel Vba Search PDF FilesShaneNo ratings yet
- FreeBSD JailsDocument172 pagesFreeBSD Jailswanna_acNo ratings yet
- ICT SA3 PracticalDocument10 pagesICT SA3 PracticalakhilsaiarushgaddamNo ratings yet
- Form - Radix PrimitivesDocument11 pagesForm - Radix PrimitivesSupremeMugwumpNo ratings yet
- Doorsrmf User GuideDocument153 pagesDoorsrmf User GuideTan HuynhNo ratings yet
- ITHArdware-Orbit 8 - ST - FactSheet - Final - 10 - 11 - 19 PDFDocument1 pageITHArdware-Orbit 8 - ST - FactSheet - Final - 10 - 11 - 19 PDFcucchitoNo ratings yet
- Timetable Management System Web ApplicatDocument17 pagesTimetable Management System Web ApplicatebaNo ratings yet
- Edc CT 1 AllotmentDocument6 pagesEdc CT 1 AllotmentD. Ravi ShankarNo ratings yet
- Copying Data From Microsoft Excel To ABAP Using OLEDocument10 pagesCopying Data From Microsoft Excel To ABAP Using OLERicky DasNo ratings yet
- Flowcharting With The ANSI Standard - A Tutorial-páginas-21-Páginas-3Document1 pageFlowcharting With The ANSI Standard - A Tutorial-páginas-21-Páginas-3ch.yacariniNo ratings yet
- An Open-Loop Sin Microstepping Driver Based On FPGA and The Co-Simulation of Modelsim and SimulinkDocument5 pagesAn Open-Loop Sin Microstepping Driver Based On FPGA and The Co-Simulation of Modelsim and SimulinkTrần Tấn LộcNo ratings yet
- AA - ChatGPT Forearning and Research Prospects andDocument9 pagesAA - ChatGPT Forearning and Research Prospects andGustavo RiveraNo ratings yet
- AutoPIPE Tutorial v6 3Document179 pagesAutoPIPE Tutorial v6 3Rolaniele A. GarciaNo ratings yet
- KanaDocument2 pagesKanaGeorge Iulian VladuNo ratings yet
- Local LiteratureDocument5 pagesLocal LiteratureSherriemae SabundoNo ratings yet
- Sap User ManagementDocument112 pagesSap User Managementrajesh1978.nair2381No ratings yet
- Week 5 Normalization Complete AaDocument41 pagesWeek 5 Normalization Complete AaRehman AzizNo ratings yet
- ALP ProgramsDocument5 pagesALP ProgramsShrihari VaidyaNo ratings yet
- 5.2 Web To Case Overview PDFDocument10 pages5.2 Web To Case Overview PDFTauseef khanNo ratings yet
- Python Project PDFDocument50 pagesPython Project PDFLattupalli Sai Sumanth ReddyNo ratings yet
- ReadmeDocument37 pagesReadmevenuramNo ratings yet
- Front and Index Page For Lab File For Grade 10Document17 pagesFront and Index Page For Lab File For Grade 10haarshit01No ratings yet
- Mainboard Msi - 7024 - 1.4Document26 pagesMainboard Msi - 7024 - 1.4Ho Thanh BinhNo ratings yet