Despite the recent progress, several challenges are emerging as more advanced FMs have been released [
219]. First, as FMs continue to increase in size, there is a need to improve the
computational efficiency for training and fine-tuning these models. Second, as an increasing number of LLMs are not open sourced, it becomes challenging to
incorporate knowledge into these models without accessing their internal parameters. Third, as LLMs are increasingly deployed in remote third-party settings,
protecting user privacy becomes increasingly important [
157]. Beyond these challenges for FMs in general, there are also many
unique challenges and risks during the process of GeoAI FM development.
5.1 Geographic Hallucination
Many LLMs have faced criticism for their tendency to produce “hallucinations”, generating content that is nonsensical, inaccurate given the context, or untruthful according to world knowledge [
64,
142,
159,
178]. Therefore, recent works have reported truthfulness evaluations with publicly available benchmarks such as TruthfulQA [
107] prior to their launch of FMs. For example, ChatGPT and GPT-4 have undergone OpenAI internal adversarially designed factuality evaluations [
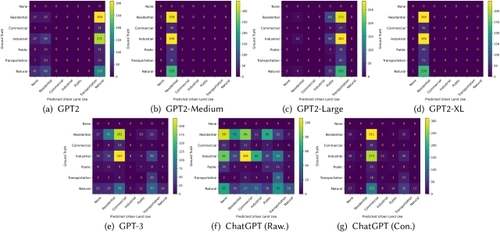
142]. Similarly, in a geographic context, generating geographic faithful results is particularly important for almost all GeoAI tasks. In addition to Figure
9 in Section
4.1, Figure
11 illustrates two geographically inaccurate results generated from ChatGPT and Stable Diffusion. In Figure
11(a), the expected answer should be “
Washington, North Carolina”.
12 However, ChatGPT indicates that there is no Washington in North Carolina. Moreover, the largest city in Washington State should be Seattle and there is no city in this state named Washington.
13 Figure
11(b) visualizes 4 generated RS images generated by Stable Diffusion.
14 Although those images appear similar to satellite images, it is rather easy to tell that they are fake RS images since the layouts of geographic features in these images are clearly not from any city in the world. In fact, generating faithful RS images is a popular and important RS task [
49,
53] in which geometric accuracy is very important for the downstream tasks.
The first step to addressing such a problem is to develop geographic truthfulness evaluation datasets for various LLMs based on their generated results formats. For example, we can construct an adversarially designed geographic question-answering dataset to evaluate the geographic truthfulness of various LLMs. In the case of image editing and generation models such as Stable Diffusion, a collection of prompt-geospatial image pairs could be gathered to evaluate the geographic accuracy of the generated content.
5.2 Geographic Bias
It is well known that FMs have the potential to amplify existing societal inequalities and biases present in the data [
14,
178,
213]. A key consideration for GeoAI in particular is
geographic bias [
38,
110,
132,
133], which is often overlooked by AI research. For example, Liu et al. [
110] showed that all current geoparsers are highly geographically biased towards data-rich regions. The same issue can be observed in current LLMs. Faisal and Anastasopoulos [
38] investigated the geographic and geopolitical bias presented in
pre-training language models (PLMs). They show that the knowledge learned by PLMs is unequally shared across languages and countries and many PLMs exhibit so-called geopolitical favoritism, which is defined as an over-amplification of certain countries’ knowledge in the learned representations (e.g., countries with higher GDP, geopolitical stability, military strength, etc.). Figure
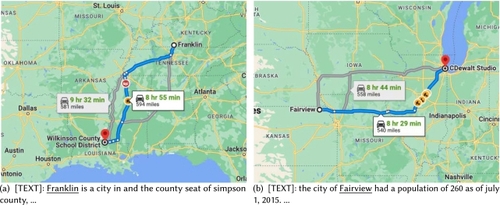
12 shows two examples in which both ChatGPT and GPT-4 generate inaccurate results due to the geographic bias inherited in these models. Compared with
“San Jose, California, USA”,
“San Jose, Batangas, Philippines”15 is a less popular place name in many text corpora. Similarly, compared with
“Washington State, USA” and
“Washington, D.C., USA”,
“Washington, New York”16 is also a less popular place name. That is why both ChatGPT and GPT-4 interpret those place names incorrectly. Compared with task-specific models, FMs suffer more from geographic bias since (1) the training data is collected in large scale, which is likely to be dominated by overrepresented communities or regions; (2) the huge number of learnable parameters and complex model structures make model interpretation and debiasing much more difficult; and (3) the geographic bias of the FMs can be easily inherited by all adapted models downstream [
14] and, thus, bring much more harm to the society. This indicates a pressing need for designing proper (geographic) debiasing frameworks.
To solve the geographic bias problem, the key is to understand the causes of geographic bias and design bespoke solutions. Liu et al. [
110] classified geographic bias into four categories: (1)
representation bias: whether the distribution of training/testing data is geographically biased; (2)
aggregation bias: whether the discretization of the space can lead to different prediction results, thus, different conclusions;
17 (3)
algorithmic bias: whether the used model will amplify or bring additional geographic bias; and (4)
evaluation bias: whether the evaluation metric can reflect fairness across geographic space.
Representation bias concerning geography is widely acknowledged. Numerous commonly used labeled geospatial datasets exhibit geographic data imbalance, including the fine-grained species recognition datasets (e.g., BirdSnap [
13], iNatlist 2018 [
27,
115,
130], iNatlist 2021 [
197], etc.), satellite image classification and object segmentation datasets (e.g., BigEarthNet [
174], SpaceNet [
179], xView [
95], Agriculture-Vision [
25], etc.), and geoparsing datasets (e.g., WikTOK [
46], GeoCorporal [
181], etc.). In addition, many general-purpose corpora such as Wikipedia and the DBpedia KG have also been found to be geographically biased [
71]. To solve this issue, except for collecting more data in the data-sparse area, we can also leverage the massive amount of unlabelled geospatial datasets (which are usually less geographically imbalanced) to perform geographic self-supervised pre-training [
127] to make FMs become more robust to the geographic bias in the labeled training datasets.
Aggregation bias is mainly caused by the common practice of performing spatial partition/discretization before AI model training [
175,
201,
221]. One possible way to avoid this is to treat the geographic space as a continuous space and learn a location-aware neural network as [
89,
120,
124,
222] did.
One example of the algorithm bias is the utilization of population bias for geoparsing [
94] – the model tends to favor ranking places with larger populations more prominently. This heuristic might negatively impact the model performance on geoparsing datasets containing many less-used place names, such as Ju2016 [
76]. Since FMs are expected to provide a generalized solution for various tasks and datasets, adding such algorithm bias may benefit some tasks but hurt others. This reminds us to systematically check for possible algorithm bias during FM design and training.
Evaluation bias is a crucial concern often overlooked in the assessment process. Many geospatial datasets (e.g., iNatlist 2018) have much less testing data on underdeveloped regions. Consequently, even if the model’s performance is subpar in these regions, it may not substantially affect the overall evaluation of the model’s performance on such a dataset. A comprehensive framework is needed to solve such bias, which includes a set of geographic bias metrics and evaluation datasets that can be used to quantify such bias. In fact, many language FMs undergo bias evaluation in terms of gender, religion, race/color, sexual orientation, age, profession, and socioeconomic status prior to their release [
142,
178,
213]. Many bias evaluation datasets are constructed for this purpose, such as CrowS-Pairs [
138], WinoGender [
166], and StereoSet [
137]. However, as far as we know, there is no such work on quantifying geographic bias in FMs. This will be an exciting future research direction.
5.3 Temporal Bias
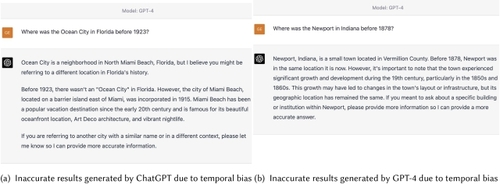
Similar to geographic bias, FMs also suffer from temporal bias, which also can be attributed to four causes: temporal representation bias, temporal aggregation bias, algorithm bias, and evaluation bias. Among them, temporal representation bias is understood to be the main driver of temporal bias since there is much more training data available for current geographic entities than for historical ones. Temporal bias can also lead to inaccurate results. Two examples are shown in Figure
13. In both cases, the names of historical places are used for other places nearby. GPT-4 fails to answer both questions due to its heavy reliance on pre-training data biased towards current geographic knowledge. Temporal bias and geographic bias are critical challenges that need to be solved for the development of GeoAI FMs.
One concrete step is to develop an evaluation framework and a dataset to quantify the temporal bias presented in various FMs. In addressing the issue of temporal bias, one potential solution entails the development of a temporal debiasing framework. Nevertheless, it’s worth noting that such a debiasing framework may have adverse effects on model performance for tasks requiring the most up-to-date information. Consequently, an alternative solution to consider is the formulation of a model fine-tuning strategy tailored to downstream tasks that involve historical events.
5.4 Low Refreshment Rate
Another temporal-related challenge is the slow refresh rate of FMs. The significant efforts, resources, and costs required to train large-scale FMs make it impractical to update them frequently. For example, ChatGPT was trained on data up to September 2021. Consequently, it cannot provide answers to questions about recent events, which is crucial in many domains, such as communication, journalism, medicine, and even AI, given the rapid pace of technological advancements, for example, chatbot applications (e.g., ChatGPT) without using external knowledge (e.g., search engines). The freshness problem can be significantly reduced when geospatial FMs are used in combination with external knowledge (e.g., maps [
104], search engines [
31,
41], or KGs) so that FMs can focus more on spatial understanding and reasoning capabilities, which need less updating over time. Nevertheless, we believe that there is a pressing need for a sustainable FM ecosystem [
170] capable of achieving efficient model training and cost-effective updates in line with the latest information. We believe this will be the next major focus in FM research.
5.6 Generalizability versus Spatial Heterogeneity
Spatial heterogeneity refers to the phenomenon that the expectation of a random variable (or a confounding of the process of discovery) varies across the Earth’s surface [
43,
100] whereas
geographic generalizability refers to the ability of a GeoAI model to replicate or generalize the model’s prediction ability across space. An open problem for GeoAI is how to achieve model generalizability (“replicability” [
43]) across space while still allowing the model to capture spatial heterogeneity. Given geospatial data with different spatial scales, we desire an FM that can learn general spatial trends while still memorizing location-specific details. Will this generalizability introduce unavoidable intrinsic model bias in downstream GeoAI tasks? Will this memorized localized information lead to an overly complicated prediction surface for a global prediction problem? With large-scale training data, this problem can be amplified and requires care.
Many spatial statistic models have been developed to capture the spatial heterogeneity while still being able to learn the general trends, such as geographic weighted regression [
17] and multiscale geographic weighted regression [
42]. However, as far as we know, all current FMs cannot capture spatial heterogeneity, thus leading to poor geographic generalizability. One possible solution is to take spatial heterogeneity into account during model pre-training and/or fine-tuning. Possible methods are a spatial heterogeneity–aware deep learning framework [
193], which automatically learns the spatial partitions and trains different deep neural networks in different partitions. Another way to increase geographic generalizability is to conduct zero-shot or few-shot learning on geographic regions with lower model performance [
100]. Another promising direction is adding location encoding [
122,
124,
127,
130] as part of the foundation model input, which can help the model adapt to different locations in a data-efficient way. How to develop a geographically generalizable (or so-called spatial replicable [
43]) deep neural net, e.g., language foundation models, is a promising research direction.